
记录一个比较有意义的故障,没遇到的可以避坑,已经被坑过的只能握手🤝了。
背景
因阿里云提示机器有故障,会在第二天早高峰自动重启,按照之前运维操作,提前做好通知后,在集群非高峰期将机器踢出集群。踢出集群时该机器上运行的 TaskManager Pod 会挂掉,Flink 会在其他正常机器上申请新的 TaskManager 运行,期间会有任务的 failover。
操作后 10 来分钟看到公司大群有值班同事响应指标异常问题,加入到问题群聊中发现可能和剔除故障机器有关,于是加入排查,提供了当时受影响的任务信息,发现了异常指标对应的任务当时在消费 10 分钟之前的数据。

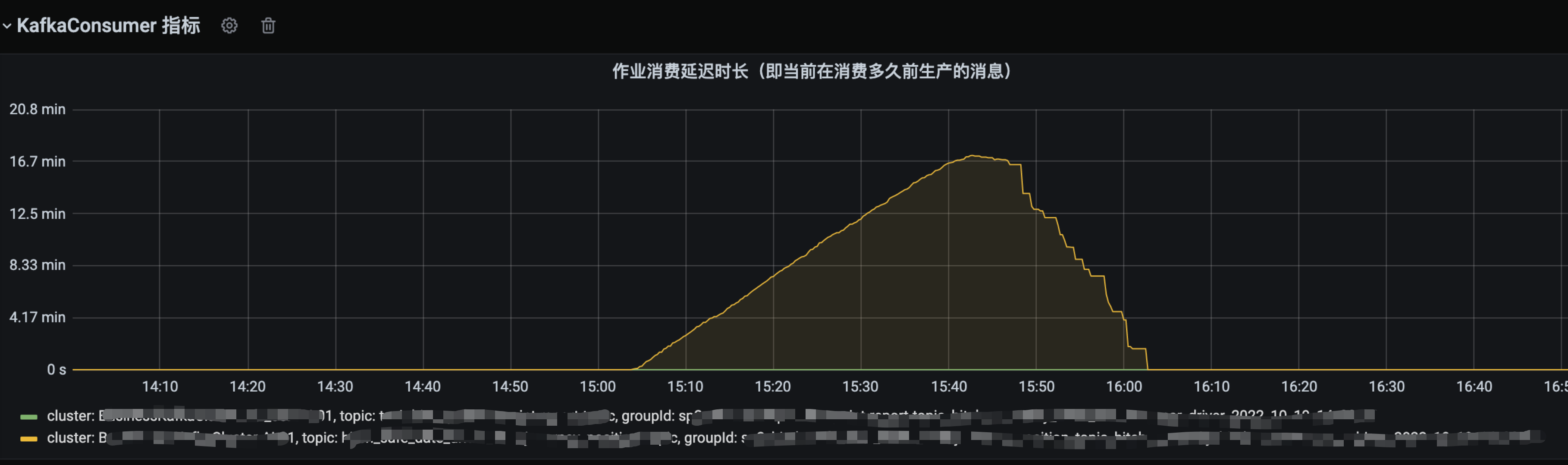
而这个消费延迟时长对于该作业的业务场景完全不能接受(延迟 10s 就会造成很大问题),最终延迟导致业务指标下跌,产生资损,故障最终定级 P3。
解决办法:业务方停了几个同步数据到 ES 索引的任务,然后重建了主链索引任务(任务同时加大并发),下游切换到新索引即恢复。
故障根因分析过程
事后找业务方线下讨论了一下,初步分析是 ES 压力大,导致 Flink 任务有反压,从而引起任务 Source 端消费 Kafka 数据导致的延迟。

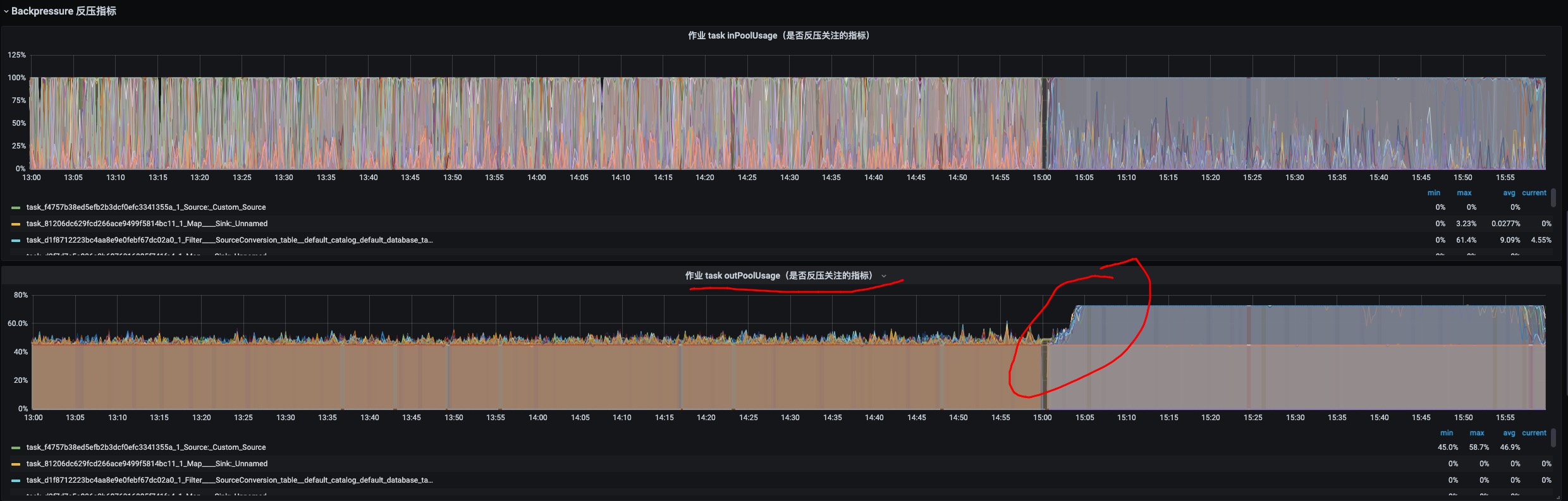
本以为结论就是剔除机器后,受影响任务比较多,任务 failover 后会从上一次 Checkpoint 保存的 Kafka offset 开始消费,这时候写到 ES 的数据量会比正常多 2min 左右的数据(Checkpoint 集群默认设置的 2min 执行一次),从而导致对 ES 有点压力进而影响到 Flink 任务出现反压情况。但是晚上业务方给我提供了一个另外受影响任务(这里称备链任务,主链任务就是那个消费 10 分钟之前数据的任务)的作业监控链接,也就是通过这个任务的监控信息才真正发现问题的根因。
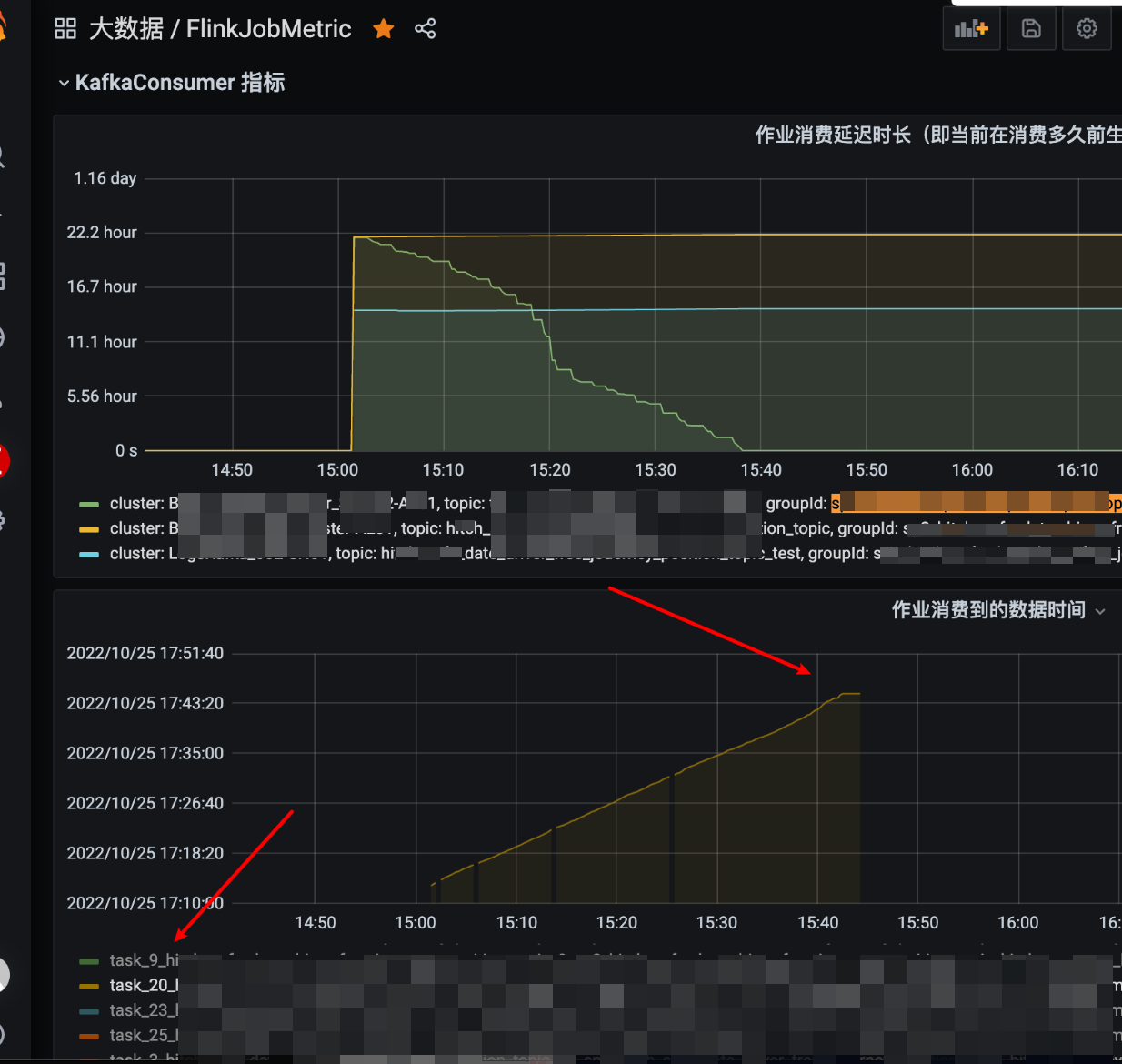
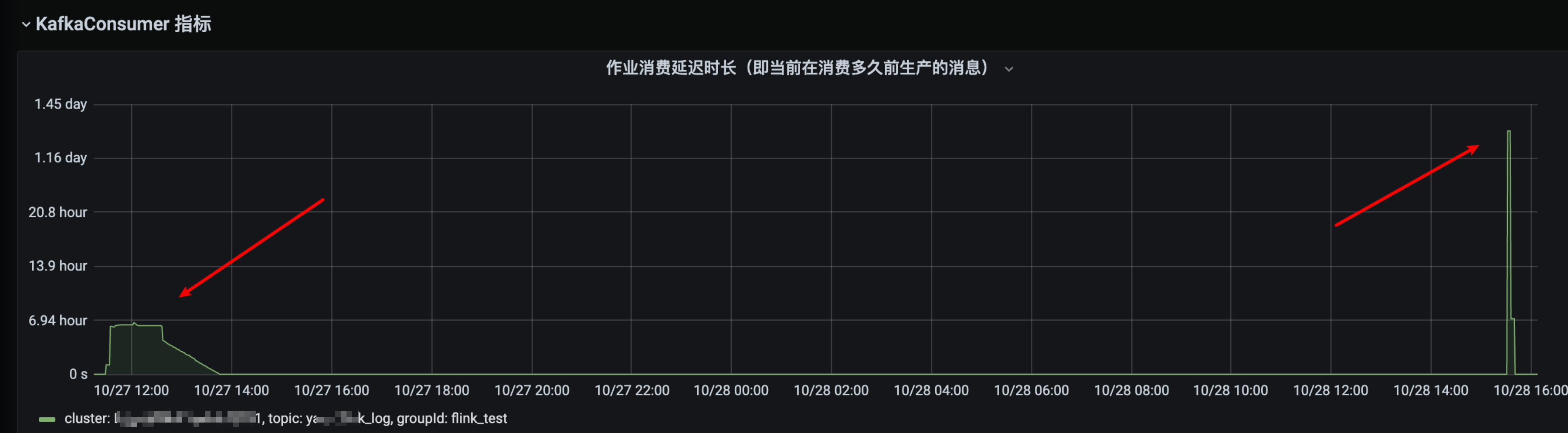
当时发现这个备链任务在故障后有大部分 TaskManager 的 task 是从 22 个小时之前的数据开始消费的,如下图监控所示:
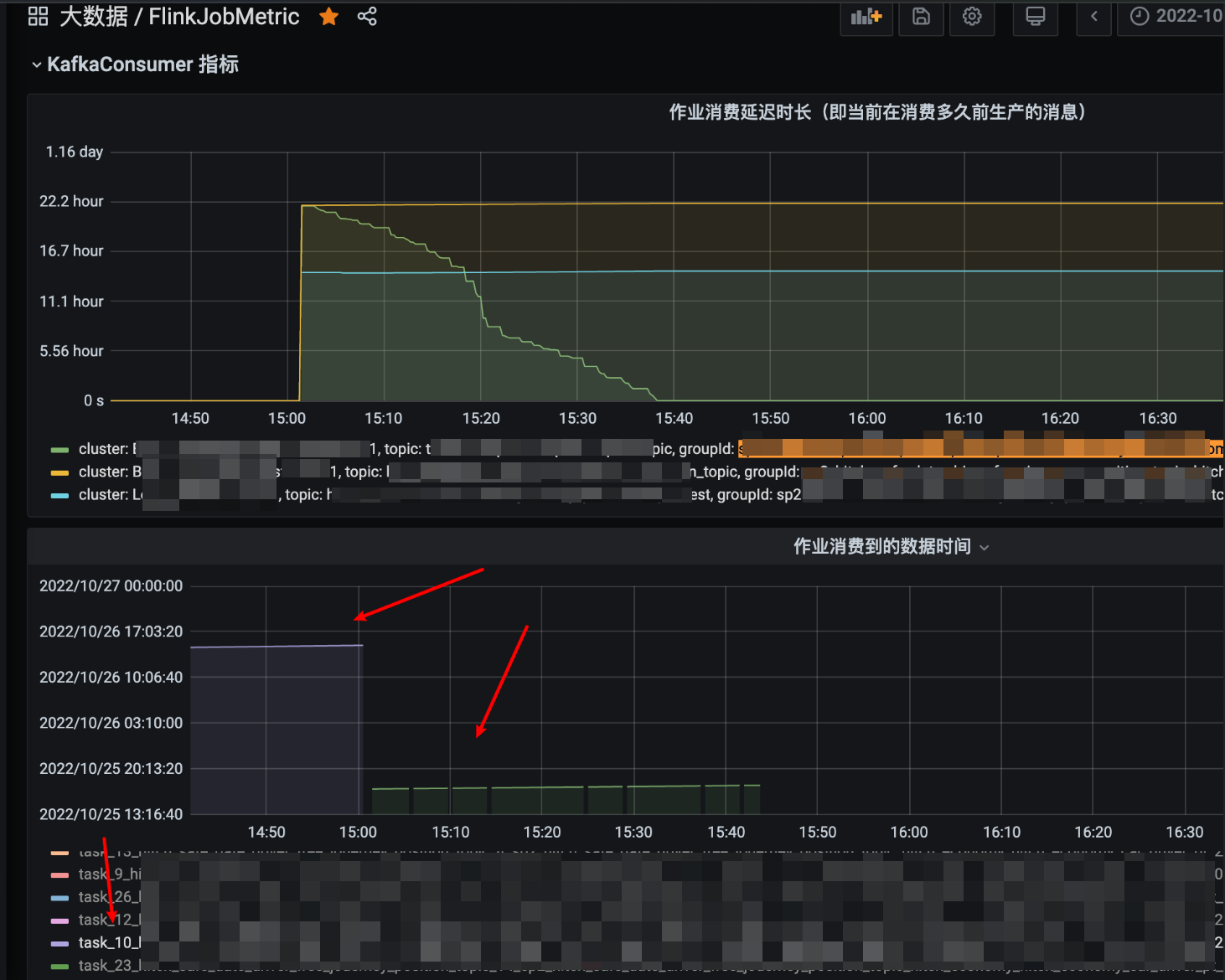
又有少部分 TaskManager 的 task 是正常消费的,如下图所示:
在 failover 之后该备链任务的消费速度 TPS 从正常的两千增长到 12W/s
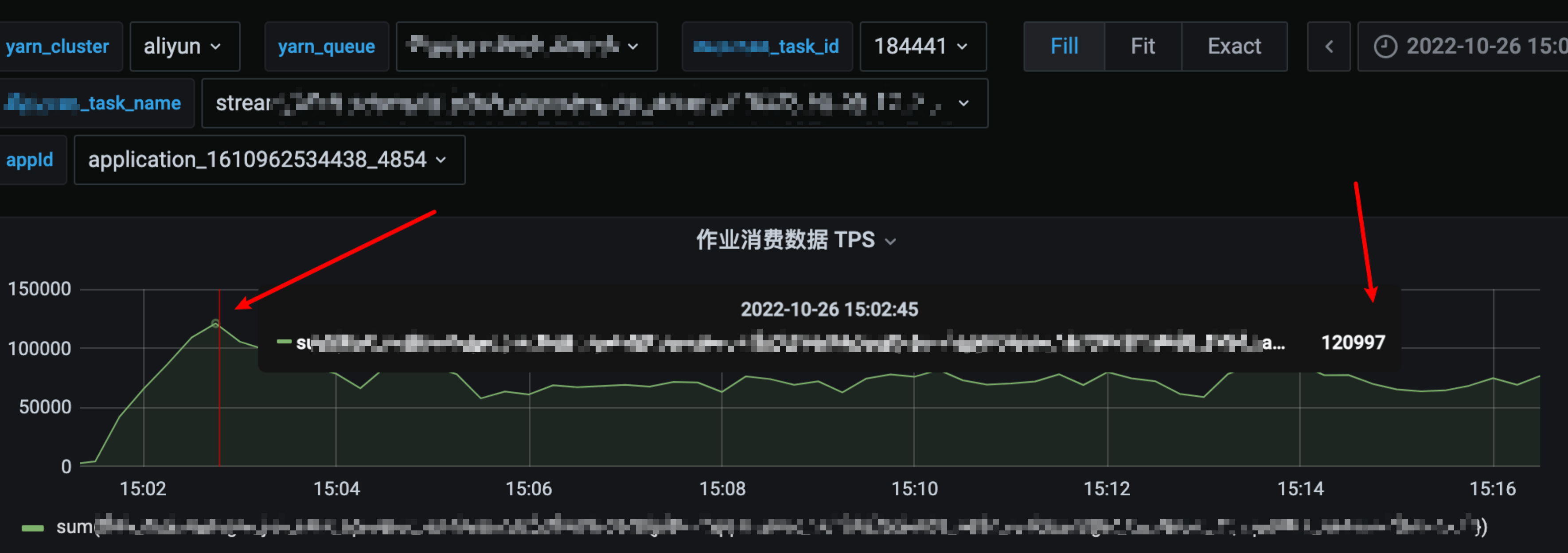
主链任务 failover 后所有的 task 消费比较正常(前文已截图),对比几个监控来看该备链任务在 failover 后明显消费有异常,即消费 22 小时之前的数据,同时看到任务启动运行时长就是 22 小时左右,相当于从任务开第一次始启动的时候指定的时间点开始消费了。
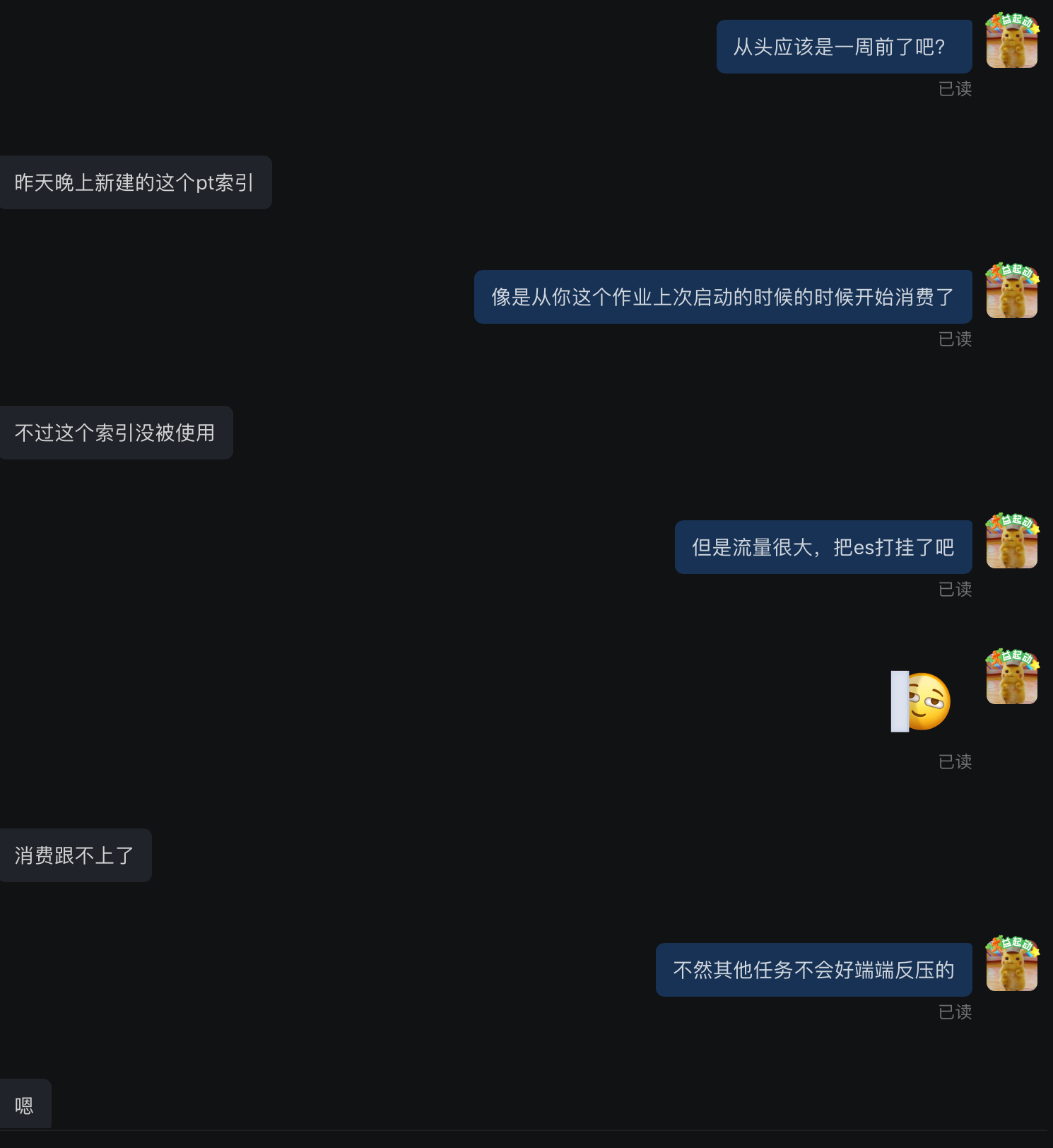
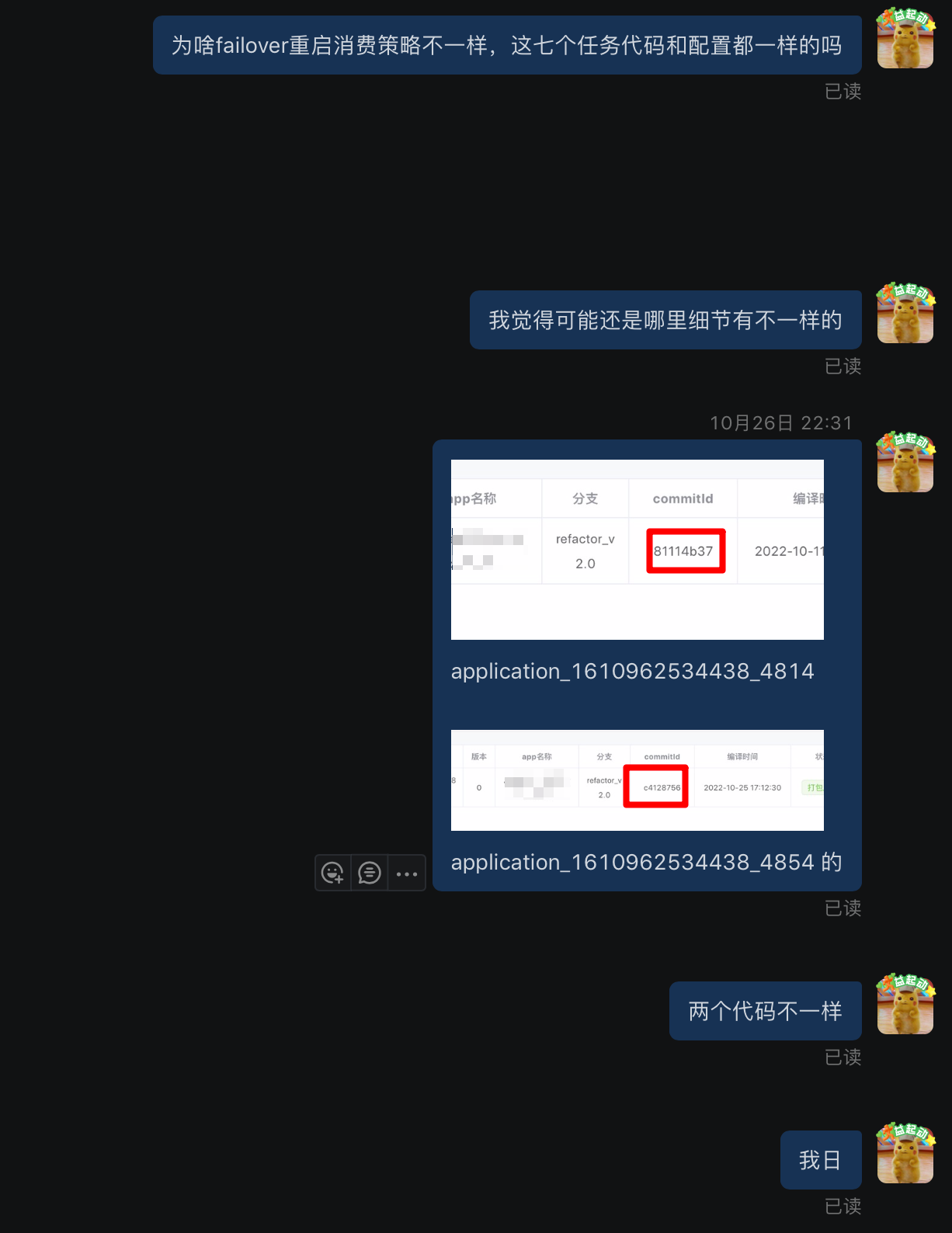
既然主链和备链任务 failover 后的消费策略都不一样,所以我当时第一反应觉得是不是备链任务长期 Checkpoint 失败,然后 failover 后从早期完成的 Checkpoint 中保存的 offset 开始消费,从而导致的消费 22 小时之前的数据,但是咨询了业务方发现任务关闭了 Checkpoint。心想那只有可能是没打开 Kafka 的 auto.commit.offset 或者打开了但是自动提交一直失败了,我去看了 Kafka topic groupid 的 committed offset 监控发现正常,一直有在正常的提交 offset,所以也否定了刚才的猜想。另外就是觉得两个任务的消费策略这么大,是不是代码不一致或者配置不一致导致的,因为一开始问了业务方代码是否一致,回复是一致的,这里我也被坑了一下,后面在平台发现两个任务的代码 Git commitId 都不一样,那也就是意味着代码不一致。
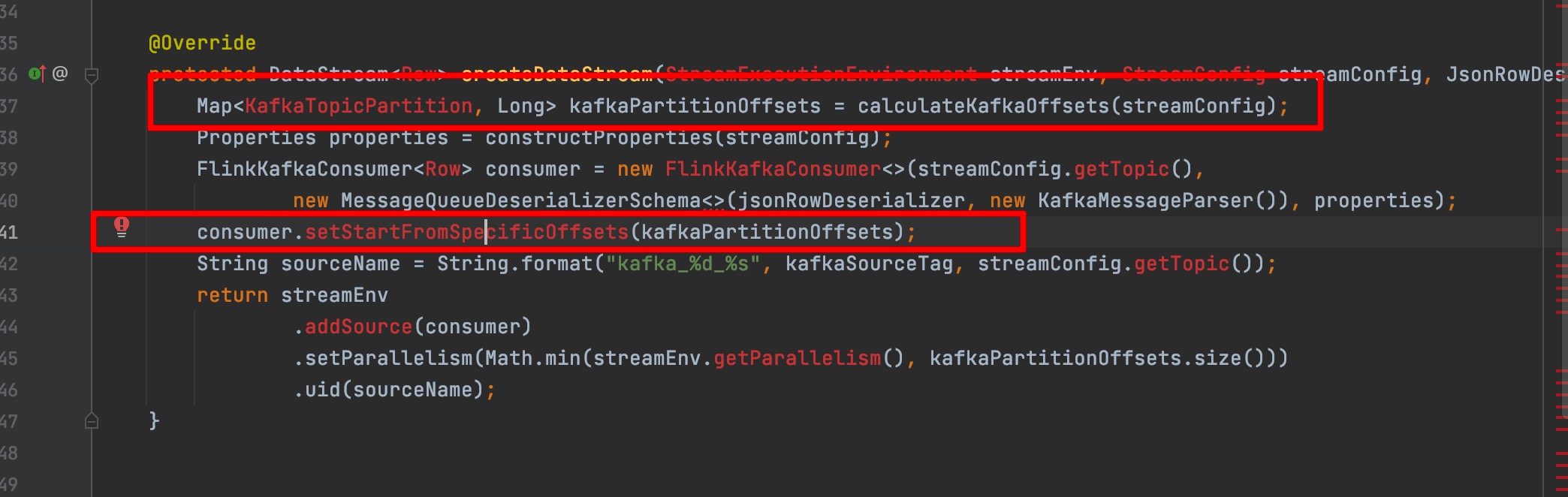
接着就开始 review 业务方的项目代码,发现备链路任务关闭了 Checkpoint,而主链任务是开启 Checkpoint 的,同时代码消费方式是指定了 Offset 开始消费(根据时间配置查询 topic 的 offset,然后从指定的 offset 开始消费,这种消费方式其实和指定 timestamp 开始消费是一致的)。
然后我就翻了下 KafkaSource Consumer 源码,如下图所示:
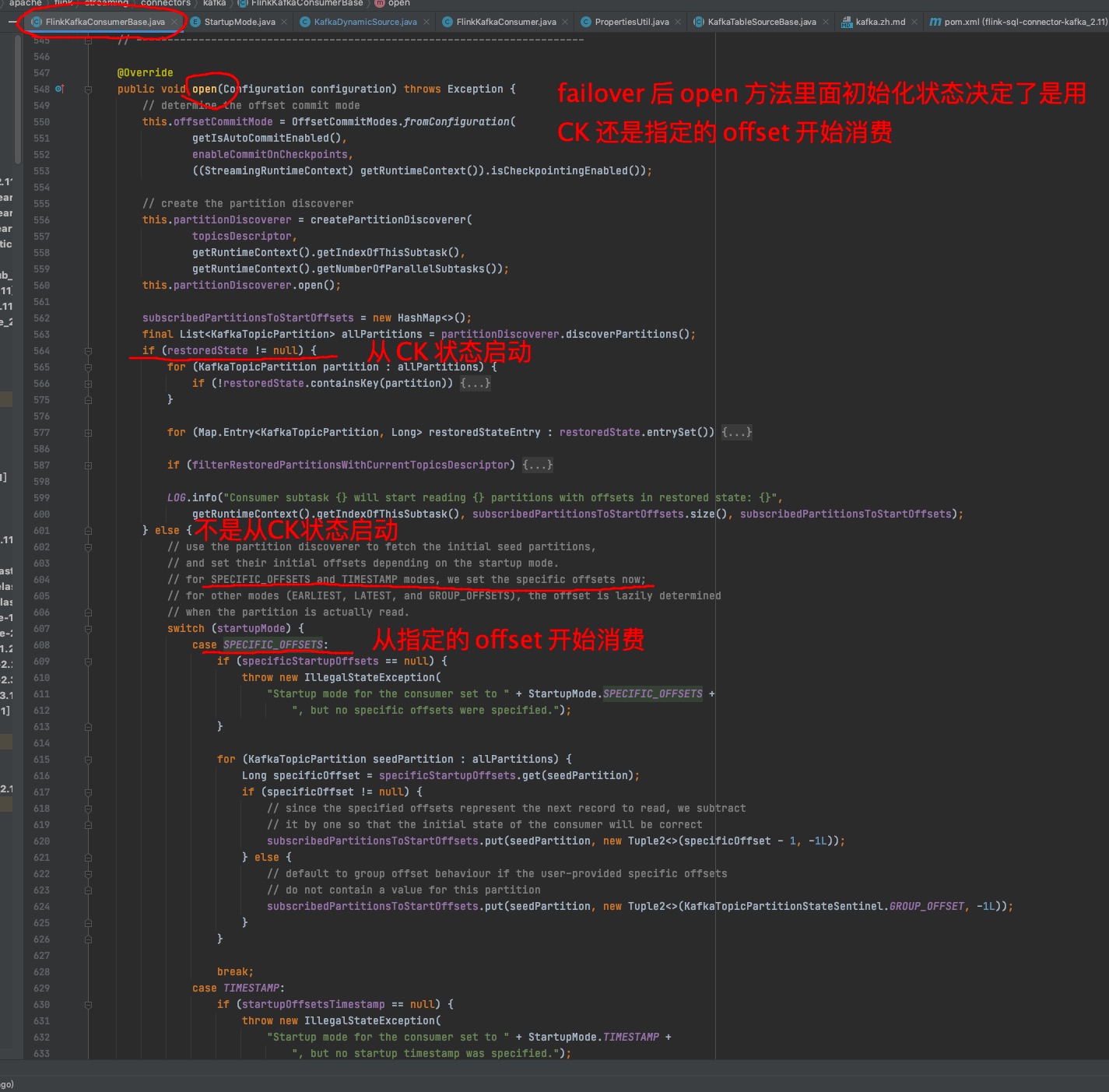
Open 方法主要做了状态初始化相关逻辑,可以发现如果关闭了 Checkpoint,那么肯定不会有恢复的状态,也就是走到后面的逻辑,按照用户指定的 offset 开始消费。在踢出故障机器后,会申请新的 TaskManager 做状态初始化其实就是会走到上面的逻辑,也就导致 failover 后消费了很早之前的数据。排查到这,几乎根因已经出来了,接下来就是验证过程。
根因验证
测试代码:
1 | 4j |
当时指定的 timestamp 是 1666819431000 (对应 2022-10-27 05:23:51),然后在 2022-10-28 15:31 时手动 Kill 掉一个 TaskManager pod,任务发生 failover,新申请的 pod 开始消费 1666819431000 (对应 2022-10-27 05:23:51)时候的数据
新申请 TM 启动日志:
1 | 2022-10-28 15:31:05,254 INFO org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase [] - Consumer subtask 0 will start reading the following 6 partitions from timestamp 1666819431000: [KafkaTopicPartition{topic='yxxx_log', partition=34}, KafkaTopicPartition{topic='yxxx_log', partition=4}, KafkaTopicPartition{topic='yxxx_log', partition=54}, KafkaTopicPartition{topic='yxxx_log', partition=24}, KafkaTopicPartition{topic='yxxx_log', partition=44}, KafkaTopicPartition{topic='yxxx_log', partition=14}] |
可以从日志发现是继续从 1666819431000 开始
结论
关闭 Checkpoint + 指定 timestamp 或者 Offset 消费 + 故障 failover 时会出现重复读数据问题
思考
1、核心任务一定要配置好消费延迟告警,及时发现和定位问题能减少故障损失
2、不要轻易漏掉某些指标,否则可能会忽略掉根因
3、关闭掉集群默认开启的配置需要谨慎,多充分测试



