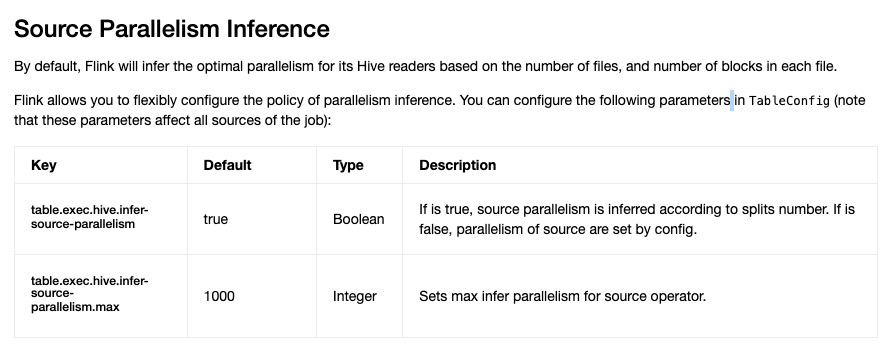
publicstaticfinal ConfigOption<Boolean> TABLE_EXEC_HIVE_INFER_SOURCE_PARALLELISM = key("table.exec.hive.infer-source-parallelism") .defaultValue(true) .withDescription( "If is false, parallelism of source are set by config.\n" + "If is true, source parallelism is inferred according to splits number.\n");
publicstaticfinal ConfigOption<Integer> TABLE_EXEC_HIVE_INFER_SOURCE_PARALLELISM_MAX = key("table.exec.hive.infer-source-parallelism.max") .defaultValue(1000) .withDescription("Sets max infer parallelism for source operator.");
/** * Apply limit to calculate the parallelism. * Here limit is the limit in query <code>SELECT * FROM xxx LIMIT [limit]</code>. */ intlimit(Long limit){ if (limit != null) { parallelism = Math.min(parallelism, (int) (limit / 1000)); }
// make sure that parallelism is at least 1 return Math.max(1, parallelism); }
//根据 /** * Infer parallelism by number of files and number of splits. * If {@link HiveOptions#TABLE_EXEC_HIVE_INFER_SOURCE_PARALLELISM} is not set this method does nothing. */ HiveParallelismInference infer( SupplierWithException<Integer, IOException> numFiles, SupplierWithException<Integer, IOException> numSplits){ //如果设置 table.exec.hive.infer-source-parallelism 为 false,则直接跳过了 if (!infer) { returnthis; }
try { // `createInputSplits` is costly, // so we try to avoid calling it by first checking the number of files // which is the lower bound of the number of splits int lowerBound = logRunningTime("getNumFiles", numFiles); if (lowerBound >= inferMaxParallelism) { parallelism = inferMaxParallelism; returnthis; }
publicstaticintgetNumFiles(List<HiveTablePartition> partitions, JobConf jobConf)throws IOException { int numFiles = 0; FileSystem fs = null; for (HiveTablePartition partition : partitions) { StorageDescriptor sd = partition.getStorageDescriptor(); org.apache.hadoop.fs.Path inputPath = new org.apache.hadoop.fs.Path(sd.getLocation()); if (fs == null) { fs = inputPath.getFileSystem(jobConf); } // it's possible a partition exists in metastore but the data has been removed if (!fs.exists(inputPath)) { continue; } numFiles += fs.listStatus(inputPath).length; } return numFiles; }
publicstatic List<HiveSourceSplit> createInputSplits( int minNumSplits, List<HiveTablePartition> partitions, JobConf jobConf)throws IOException { List<HiveSourceSplit> hiveSplits = new ArrayList<>(); FileSystem fs = null; for (HiveTablePartition partition : partitions) { StorageDescriptor sd = partition.getStorageDescriptor(); org.apache.hadoop.fs.Path inputPath = new org.apache.hadoop.fs.Path(sd.getLocation()); if (fs == null) { fs = inputPath.getFileSystem(jobConf); } // it's possible a partition exists in metastore but the data has been removed if (!fs.exists(inputPath)) { continue; } InputFormat format; try { format = (InputFormat) Class.forName(sd.getInputFormat(), true, Thread.currentThread().getContextClassLoader()).newInstance(); } catch (Exception e) { thrownew FlinkHiveException("Unable to instantiate the hadoop input format", e); } ReflectionUtils.setConf(format, jobConf); jobConf.set(INPUT_DIR, sd.getLocation()); //TODO: we should consider how to calculate the splits according to minNumSplits in the future. org.apache.hadoop.mapred.InputSplit[] splitArray = format.getSplits(jobConf, minNumSplits); for (org.apache.hadoop.mapred.InputSplit inputSplit : splitArray) { Preconditions.checkState(inputSplit instanceof FileSplit, "Unsupported InputSplit type: " + inputSplit.getClass().getName()); hiveSplits.add(new HiveSourceSplit((FileSplit) inputSplit, partition, null)); } }
int lowerBound = logRunningTime("getNumFiles", numFiles); if (lowerBound >= inferMaxParallelism) { parallelism = inferMaxParallelism; returnthis; }
int splitNum = logRunningTime("createInputSplits", numSplits); parallelism = Math.min(splitNum, inferMaxParallelism);
然后就是 limit 方法的限制并行度了:
1 2 3 4 5 6 7 8 9 10 11 12
/** * Apply limit to calculate the parallelism. * Here limit is the limit in query <code>SELECT * FROM xxx LIMIT [limit]</code>. */ intlimit(Long limit){ if (limit != null) { parallelism = Math.min(parallelism, (int) (limit / 1000)); }
// make sure that parallelism is at least 1 return Math.max(1, parallelism); }