
前言
之前在 《从0到1学习Flink》—— Flink 配置文件详解 讲过 Flink 的配置,但是后面陆续有人来问我一些配置相关的东西,在加上我现在对 Flink 也更熟悉了些,这里我就再写下 Flink JobManager 的配置相关信息。
在 《从0到1学习Flink》—— Apache Flink 介绍 一文中介绍过了 Flink Job 的运行架构图:

JobManager 协调每个 Flink 作业的部署。它负责调度和资源管理。
默认情况下,每个 Flink 集群都有一个 JobManager 实例。这会产生单点故障(SPOF):如果 JobManager 崩溃,则无法提交新作业且运行中的作业也会失败。
如果我们使用 JobManager 高可用模式,可以避免这个问题。您可以为 standalone 集群和 YARN 集群配置高可用模式。
standalone 集群高可用性
standalone 集群的 JobManager 高可用性的概念是,任何时候都有一个主 JobManager 和 多个备 JobManagers,以便在主节点失败时有新的 JobNamager 接管集群。这样就保证了没有单点故障,一旦备 JobManager 接管集群,作业就可以依旧正常运行。主备 JobManager 实例之间没有明确的区别。每个 JobManager 都可以充当主备节点。
例如,请考虑以下三个 JobManager 实例的设置:

如何配置
要启用 JobManager 高可用性功能,您必须将高可用性模式设置为 zookeeper,配置 ZooKeeper quorum,将所有 JobManagers 主机及其 Web UI 端口写入配置文件。
Flink 利用 ZooKeeper 在所有正在运行的 JobManager 实例之间进行分布式协调。ZooKeeper 是独立于 Flink 的服务,通过 leader 选举和轻量级一致性状态存储提供高可靠的分布式协调服务。Flink 包含用于 Bootstrap ZooKeeper 安装的脚本。
他在我们的 Flink 安装路径下面 /conf/zoo.cfg 。

Masters 文件
要启动 HA 集群,请在以下位置配置 Masters 文件 conf/masters:
1 | localhost:8081 |
masters 文件包含启动 JobManagers 的所有主机以及 Web 用户界面绑定的端口,上面一行写一个。
默认情况下,job manager 选一个随机端口作为进程通信端口。您可以通过 high-availability.jobmanager.port 更改此设置。此配置接受单个端口(例如 50010),范围(50000-50025)或两者的组合(50010,50011,50020-50025,50050-50075)。
配置文件 (flink-conf.yaml)
要启动 HA 集群,请将以下配置键添加到 conf/flink-conf.yaml:
高可用性模式(必需):在 conf/flink-conf.yaml中,必须将高可用性模式设置为 zookeeper,以打开高可用模式。
1 | high-availability: zookeeper |
ZooKeeper quorum(必需):ZooKeeper quorum 是一组 ZooKeeper 服务器,它提供分布式协调服务。
1 | high-availability.zookeeper.quorum: ip1:2181 [,...],ip2:2181 |
每个 ip:port 都是一个 ZooKeeper 服务器的 ip 及其端口,Flink 可以通过指定的地址和端口访问 zookeeper。
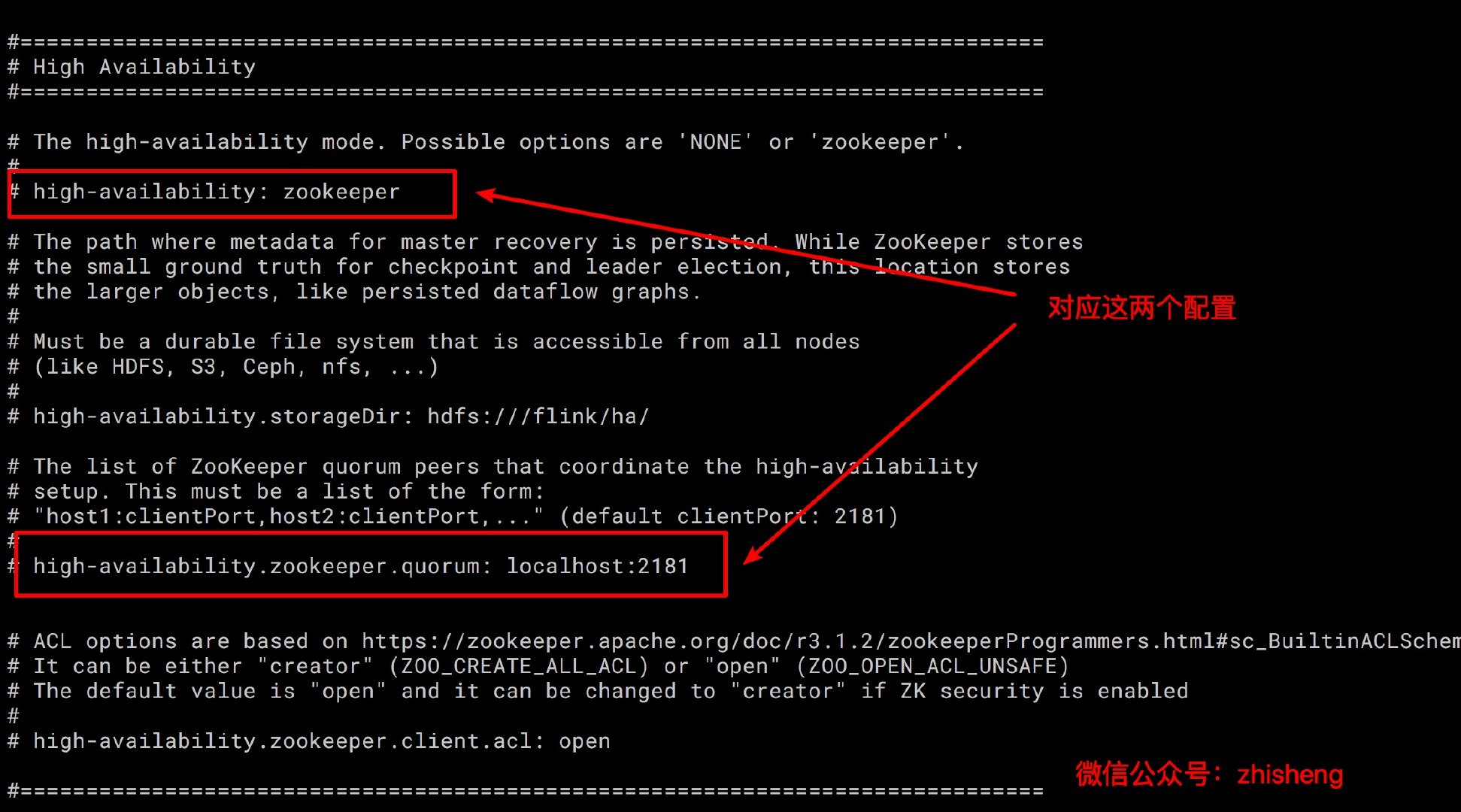
另外就是高可用存储目录,JobManager 元数据保存在文件系统 storageDir 中,在 ZooKeeper 中仅保存了指向此状态的指针, 推荐这个目录是 HDFS, S3, Ceph, nfs 等,该 storageDir 中保存了 JobManager 恢复状态需要的所有元数据。
1 | high-availability.storageDir: hdfs:///flink/ha/ |
配置 master 文件和 ZooKeeper 配置后,您可以使用提供的集群启动脚本。他们将启动 HA 集群。请注意,启动 Flink HA 集群前,必须启动 Zookeeper 集群,并确保为要启动的每个 HA 集群配置单独的 ZooKeeper 根路径。
示例
具有 2 个 JobManagers 的 Standalone 集群:
1、在 conf/flink-conf.yaml 中配置高可用模式和 Zookeeper :
1 | high-availability: zookeeper |
2、在 conf/masters 中 配置 masters:
1 | localhost:8081 |
3、在 conf/zoo.cfg 中配置 Zookeeper 服务:
1 | server.0=localhost:2888:3888 |
4、启动 ZooKeeper 集群:
1 | $ bin/start-zookeeper-quorum.sh |
5、启动一个 Flink HA 集群:
1 | $ bin/start-cluster.sh |
6、停止 ZooKeeper 和集群:
1 | $ bin/stop-cluster.sh |
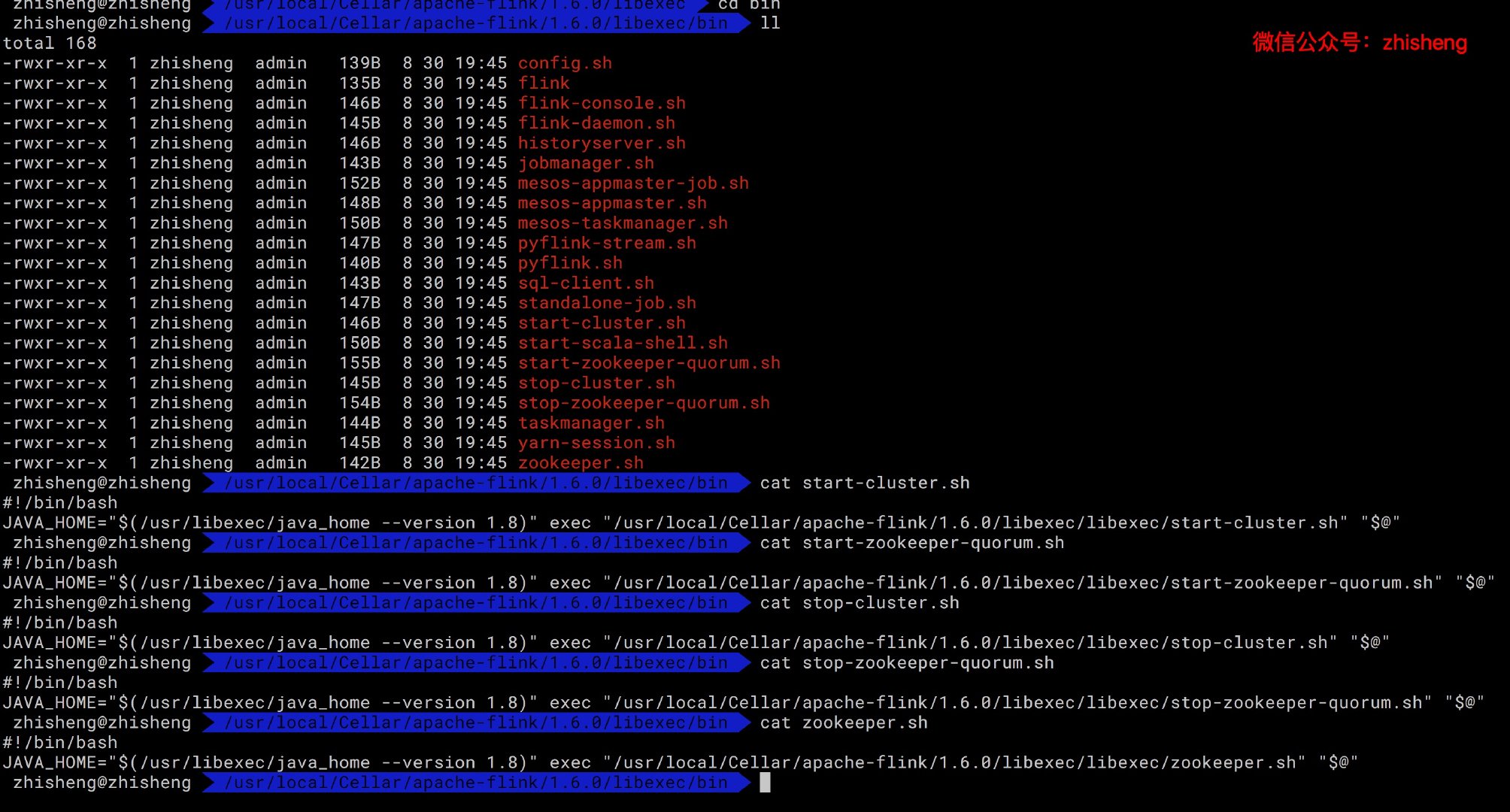
上面的执行脚本如下图可见:
YARN 集群高可用性
当运行高可用的 YARN 集群时,我们不会运行多个 JobManager 实例,而只会运行一个,该 JobManager 实例失败时,YARN 会将其重新启动。Yarn 的具体行为取决于您使用的 YARN 版本。
如何配置?
Application Master 最大重试次数 (yarn-site.xml)
在 YARN 配置文件 yarn-site.xml 中,需要配置 application master 的最大重试次数:
1 | <property> |
当前 YARN 版本的默认值为 2(表示允许单个 JobManager 失败两次)。
Application Attempts (flink-conf.yaml)
除了上面可以配置最大重试次数外,你还可以在 flink-conf.yaml 配置如下:
1 | yarn.application-attempts: 10 |
这意味着在如果程序启动失败,YARN 会再重试 9 次(9 次重试 + 1 次启动),如果启动 10 次作业还失败,yarn 才会将该任务的状态置为失败。如果因为节点硬件故障或重启,NodeManager 重新同步等操作,需要 YARN 继续尝试启动应用。这些重启尝试不计入 yarn.application-attempts 个数中。
容器关闭行为
- YARN 2.3.0 < 版本 < 2.4.0. 如果 application master 进程失败,则所有的 container 都会重启。
- YARN 2.4.0 < 版本 < 2.6.0. TaskManager container 在 application master 故障期间,会继续工作。这具有以下优点:作业恢复时间更快,且缩短所有 task manager 启动时申请资源的时间。
- YARN 2.6.0 <= version: 将尝试失败有效性间隔设置为 Flink 的 Akka 超时值。尝试失败有效性间隔表示只有在系统在一个间隔期间看到最大应用程序尝试次数后才会终止应用程序。这避免了持久的工作会耗尽它的应用程序尝试。
示例:高可用的 YARN Session
1、配置 HA 模式和 Zookeeper 集群 在 conf/flink-conf.yaml:1
2
3high-availability: zookeeper
high-availability.zookeeper.quorum: localhost:2181
yarn.application-attempts: 10
2、配置 ZooKeeper 服务 在 conf/zoo.cfg:1
server.0=localhost:2888:3888
3、启动 Zookeeper 集群:1
2$ bin/start-zookeeper-quorum.sh
Starting zookeeper daemon on host localhost.
4、启动 HA 集群:1
$ bin/yarn-session.sh -n 2
总结
本篇文章再次写了下 Flink JobManager 的高可用配置,如何在 standalone 集群和 YARN 集群中配置高可用。
关注我
转载请务必注明原创地址为:http://www.54tianzhisheng.cn/2019/01/13/Flink-JobManager-High-availability/ , 未经允许禁止转载。
微信公众号:zhisheng
另外我自己整理了些 Flink 的学习资料,目前已经全部放到微信公众号(zhisheng)了,你可以回复关键字:Flink 即可无条件获取到。另外也可以加我微信 你可以加我的微信:yuanblog_tzs,探讨技术!

更多私密资料请加入知识星球!

专栏介绍
扫码下面专栏二维码可以订阅该专栏

首发地址:http://www.54tianzhisheng.cn/2019/11/15/flink-in-action/
专栏地址:https://gitbook.cn/gitchat/column/5dad4a20669f843a1a37cb4f
Github 代码仓库
https://github.com/zhisheng17/flink-learning/
以后这个项目的所有代码都将放在这个仓库里,包含了自己学习 flink 的一些 demo 和博客
博客
1、Flink 从0到1学习 —— Apache Flink 介绍
2、Flink 从0到1学习 —— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
3、Flink 从0到1学习 —— Flink 配置文件详解
4、Flink 从0到1学习 —— Data Source 介绍
5、Flink 从0到1学习 —— 如何自定义 Data Source ?
6、Flink 从0到1学习 —— Data Sink 介绍
7、Flink 从0到1学习 —— 如何自定义 Data Sink ?
8、Flink 从0到1学习 —— Flink Data transformation(转换)
9、Flink 从0到1学习 —— 介绍 Flink 中的 Stream Windows
10、Flink 从0到1学习 —— Flink 中的几种 Time 详解
11、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 ElasticSearch
12、Flink 从0到1学习 —— Flink 项目如何运行?
13、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Kafka
14、Flink 从0到1学习 —— Flink JobManager 高可用性配置
15、Flink 从0到1学习 —— Flink parallelism 和 Slot 介绍
16、Flink 从0到1学习 —— Flink 读取 Kafka 数据批量写入到 MySQL
17、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RabbitMQ
18、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HBase
19、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HDFS
20、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Redis
21、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Cassandra
22、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Flume
23、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 InfluxDB
24、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RocketMQ
25、Flink 从0到1学习 —— 你上传的 jar 包藏到哪里去了
26、Flink 从0到1学习 —— 你的 Flink job 日志跑到哪里去了
28、Flink 从0到1学习 —— Flink 中如何管理配置?
29、Flink 从0到1学习—— Flink 不可以连续 Split(分流)?
30、Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
32、为什么说流处理即未来?
33、OPPO 数据中台之基石:基于 Flink SQL 构建实时数据仓库
36、Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
38、如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
40、Flink 全网最全资源(视频、博客、PPT、入门、实战、源码解析、问答等持续更新)
42、Flink 从0到1学习 —— 如何使用 Side Output 来分流?
源码解析
4、Flink 源码解析 —— standalone session 模式启动流程
5、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Job Manager 启动
6、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Task Manager 启动
7、Flink 源码解析 —— 分析 Batch WordCount 程序的执行过程
8、Flink 源码解析 —— 分析 Streaming WordCount 程序的执行过程
9、Flink 源码解析 —— 如何获取 JobGraph?
10、Flink 源码解析 —— 如何获取 StreamGraph?
11、Flink 源码解析 —— Flink JobManager 有什么作用?
12、Flink 源码解析 —— Flink TaskManager 有什么作用?
13、Flink 源码解析 —— JobManager 处理 SubmitJob 的过程
14、Flink 源码解析 —— TaskManager 处理 SubmitJob 的过程
15、Flink 源码解析 —— 深度解析 Flink Checkpoint 机制
16、Flink 源码解析 —— 深度解析 Flink 序列化机制
17、Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
18、Flink Metrics 源码解析 —— Flink-metrics-core
19、Flink Metrics 源码解析 —— Flink-metrics-datadog
20、Flink Metrics 源码解析 —— Flink-metrics-dropwizard
21、Flink Metrics 源码解析 —— Flink-metrics-graphite
22、Flink Metrics 源码解析 —— Flink-metrics-influxdb
23、Flink Metrics 源码解析 —— Flink-metrics-jmx
24、Flink Metrics 源码解析 —— Flink-metrics-slf4j
25、Flink Metrics 源码解析 —— Flink-metrics-statsd
26、Flink Metrics 源码解析 —— Flink-metrics-prometheus

27、Flink 源码解析 —— 如何获取 ExecutionGraph ?


