
第十二章 —— Flink 案例
本章将介绍 Flink 在多个场景下落地实现的大型案例,第一个是实时处理海量的日志,将从日志的收集、日志的传输、日志的实时清洗和异常检测、日志存储、日志展示等方面去介绍 Flink 在其中起的作用,希望整个日志处理的架构大家可以灵活的运用在自己的公司;第二个是百亿数据量的情况下如何使用 Flink 实时去重,在这个案例中将对比介绍其他几种常见的去重实现方案;第三个是 Flink 在监控告警系统中的落地实现,在这个案例中同样很详细的介绍了一个监控告警系统的全链路,每一个关节都不可或缺,并且还介绍了 Flink 在未来结合机器学习算法做一些 AIOps 的事情。三个案例都比较典型,如果你也在做类似的项目,希望对你们的技术选型有一定的帮助。
12.1 基于 Flink 实时处理海量日志
在 11.5 节中讲解了 Flink 如何实时处理异常的日志,并且对比分析了几种常用的日志采集工具。我们也知道通常在排查线上异常故障的时候,日志是必不可缺的一部分,通过异常日志我们可以快速的定位到问题的根因。那么通常在公司对于日志处理有哪些需求呢?
12.1.1 实时处理海量日志需求分析
现在公司都在流行构建分布式、微服务、云原生的架构,在这类架构下,项目应用的日志都被分散到不同的机器上,日志查询就会比较困难,所以统一的日志收集几乎也是每家公司必不可少的。据笔者调研,不少公司现在是有日志统一的收集,也会去做日志的实时 ETL,利用一些主流的技术比如 ELK 去做日志的展示、搜索和分析,但是却缺少了日志的实时告警。总结来说,大部分公司对于日志这块的现状是:
- 日志分布零散:分布式应用导致日志分布在不同的机器上,人肉登录到机器上操作复杂,需要统一的日志收集工具。
- 异常日志无告警:出错时无异常日志告警,导致错过最佳定位问题的时机,需要异常错误日志的告警。
- 日志查看不友好:登录服务器上在终端查看日志不太方便,需要一个操作友好的页面去查看日志。
- 无日志搜索分析:历史日志文件太多,想找某种日志找不到了,需要一个可以搜索日志的功能。
在本节中,笔者将为大家讲解日志的全链路,包含了日志的实时采集、日志的 ETL、日志的实时监控告警、日志的存储、日志的可视化图表展示与搜索分析等。
12.1.2 实时处理海量日志架构设计
分析完我们这个案例的需求后,接下来对整个项目的架构做一个合理的设计。
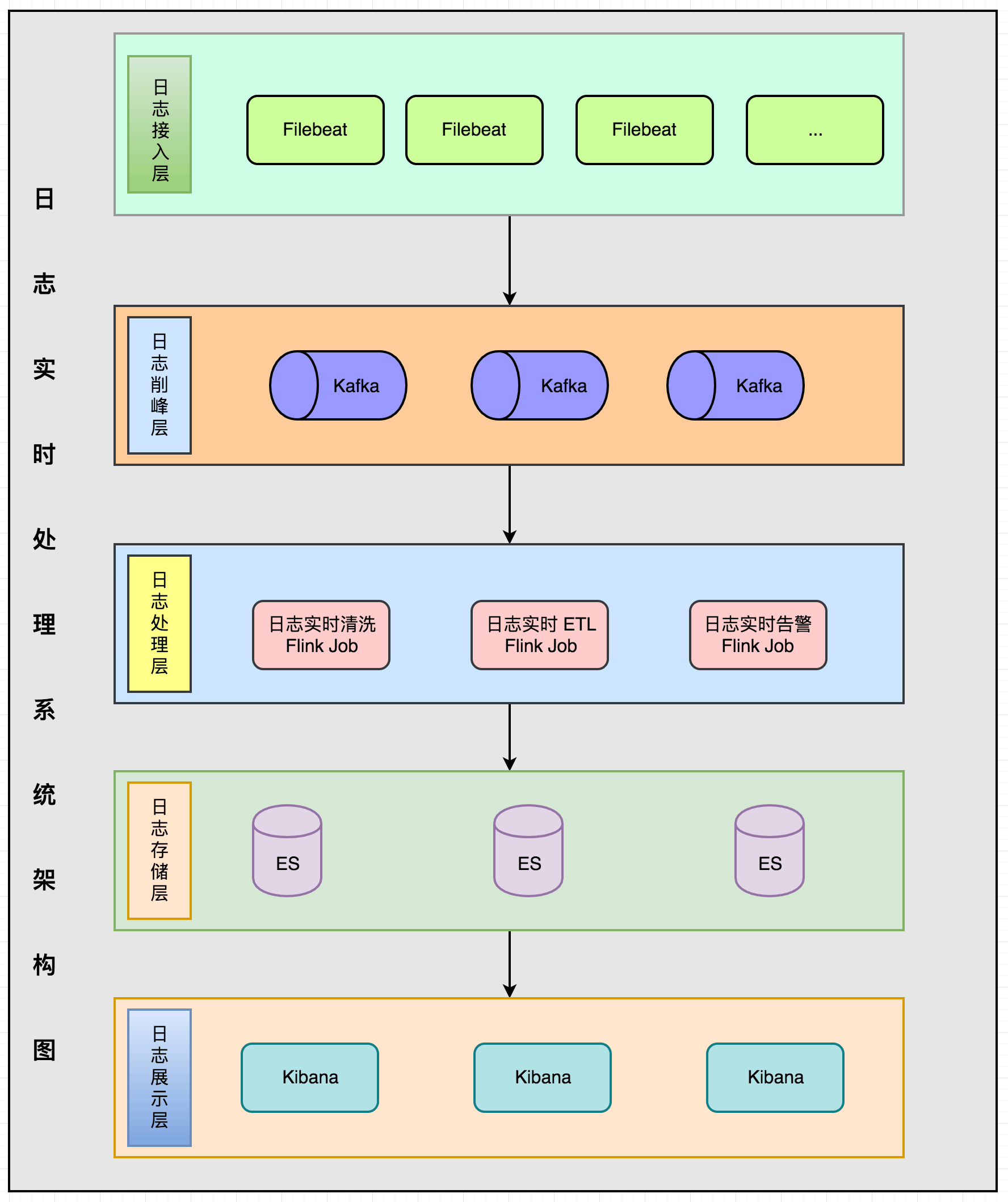
整个架构分为五层:日志接入层、日志削峰层、日志处理层、日志存储层、日志展示层。
- 日志接入层:日志采集的话使用的是 Filebeat 组件,需要在每台机器上部署一个 Filebeat。
- 日志削峰层:防止日志流量高峰,使用 Kafka 消息队列做削峰。
- 日志处理层:Flink 作业同时消费 Kafka 数据做日志清洗、ETL、实时告警。
- 日志存储层:使用 ElasticSearch 做日志的存储。
- 日志展示层:使用 Kibana 做日志的展示与搜索查询界面。
12.1.3 日志实时采集
在 11.5.1 中对比了这几种比较流行的日志采集工具(Logstash、Filebeat、Fluentd、Logagent),从功能完整性、性能、成本、使用难度等方面综合考虑后,这里演示使用的是 Filebeat。
安装 Filebeat
在服务器上下载 Fliebeat 6.3.2 安装包(请根据自己服务器和所需要的版本进行下载),下载后进行解压。
1 | tar xzf filebeat-6.3.2-linux-x86_64.tar.gz |
配置 Filebeat
配置 Filebeat 需要编辑 Filebeat 的配置文件 filebeat.yml,不同安装方式配置文件的存放路径有一些不同,对于解压包安装的方式,配置文件存在解压目录下面;对于 rpm 和 deb 的方式, 配置文件路径的是 /etc/filebeat/filebeat.yml 下。
因为 Filebeat 是要实时采集日志的,所以得让 Filebeat 知道日志的路径是在哪里,下面在配置文件中定义一下日志文件的路径。通常建议在服务器上固定存放日志的路径,然后应用的日志都打在这个固定的路径中,这样 Filebeat 的日志路径配置只需要填写一次,其他机器上可以拷贝同样的配置就能将 Filebeat 运行起来,配置如下。
1 | - type: log |
上面的配置表示将对 /var/logs 目录下所有以 .log 结尾的文件进行采集,接下来配置日志输出的方式,这里使用的是 Kafka,配置如下。
1 | output.kafka: |
上面讲解的两个配置,笔者这里将它们写在一个新建的配置文件中 kafka.yml,然后启动 Filebeat 的时候使用该配置。
1 | filebeat.inputs: |
启动 Filebeat
日志路径的配置和 Kafka 的配置都写好后,则接下来通过下面命令将 Filebeat 启动:
1 | bin/filebeat -e -c kafka.yml |
执行完命令后出现的日志如下则表示启动成功了,另外还可以看得到会在终端打印出 metrics 数据出来。
验证 Filebeat 是否将日志数据发到 Kafka
那么此时就得去查看是否真正就将这些日志数据发到 Kafka 了呢,你可以通过 Kafka 的自带命令去消费这个 Topic 看是否不断有数据发出来,命令如下:
1 | bin/kafka-console-consumer.sh --zookeeper 106.54.248.27:2181 --topic zhisheng_log --from-beginning |
如果出现数据则代表是已经有数据发到 Kafka 了,如果你不喜欢使用这种方式验证,可以自己写个 Flink Job 去读取 Kafka 该 Topic 的数据,比如写了个作业运行结果如下就代表着日志数据已经成功发送到 Kafka。

发到 Kafka 的日志结构
既然数据都已经发到 Kafka 了,通过消费 Kafka 该 Topic 的数据我们可以发现这些数据的格式否是 JSON,结构如下:
1 | { |
这个日志结构里面包含了很多字段,比如 timestamp、metadata、host、source、message 等,但是其中某些字段我们其实根本不需要的,你可以根据公司的需求丢弃一些字段,把要丢弃的字段也配置在 kafka.yml 中,如下所示。
1 | processors: |
然后再次启动 Filebeat ,发现上面配置的字段在新的数据中没有了(除 @metadata 之外),另外经笔者验证:不仅 @metadata 字段不能丢弃,如果 @timestamp 这个字段在 drop_fields 中配置了,也是不起作用的,它们两不允许丢弃。通常来说一行日志已经够长了,再加上这么多我们不需要的字段,就会增加数据的大小,对于生产环境的话,日志数据量非常大,那无疑会对后面所有的链路都会造成一定的影响,所以一定要在底层数据源头做好精简。另外还可以在发送 Kafka 的时候对数据进行压缩,可以在配置文件中配置一个 compression: gzip。精简后的日志数据结构如下:
1 | { |
12.1.4 日志格式统一
因为 Filebeat 是在机器上采集的日志,这些日志的种类比较多,常见的有应用程序的运行日志、作业构建编译打包的日志、中间件服务运行的日志等。通常在公司是可以给开发约定日志打印的规则,但是像中间件这类服务的日志是不固定的,如果将 Kafka 中的消息直接存储到 ElasticSearch 的话,后面如果要做区分筛选的话可能会有问题。为了避免这个问题,我们得在日志存入 ElasticSearch 之前做一个数据格式化和清洗的工作,因为 Flink 处理数据的速度比较好,而且可以做到实时,所以选择在 Flink Job 中完成该工作。
在该作业中的要将 message 解析,一般该行日志信息会包含很多信息,比如日志打印时间、日志级别、应用名、唯一性 ID(用来关联各个请求)、请求上下文。那么我们就需要一个新的日志结构对象来统一日志的格式,定义如下:
12.1.5 日志实时清洗
12.1.6 日志实时告警
12.1.7 日志实时存储
12.1.8 日志实时展示
12.1.9 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/IeAYbEy



