
第四章 —— Flink 中的状态及容错机制
Flink 对比其他的流处理框架最大的特点是其支持状态,本章将深度的讲解 Flink 中的状态分类,如何在不同的场景使用不同的状态,接着会介绍 Flink 中的多种状态存储,最后会介绍 Checkpoint 和 Savepoint 的使用方式以及如何恢复状态。
4.1 深度讲解 Flink 中的状态
在基础篇中的 1.2 节中介绍了 Flink 是一款有状态的流处理框架。那么大家可能有点疑问,这个状态是什么意思?拿 Flink 最简单的 Word Count 程序来说,它需要不断的对 word 出现的个数进行结果统计,那么后一个结果就需要利用前一个的结果然后再做 +1 的操作,这样前一个计算就需要将 word 出现的次数 count 进行存着(这个 count 那么就是一个状态)然后后面才可以进行累加。
4.1.1 为什么需要 State?
对于流处理系统,数据是一条一条被处理的,如果没有对数据处理的进度进行记录,那么如果这个处理数据的 Job 因为机器问题或者其他问题而导致重启,那么它是不知道上一次处理数据是到哪个地方了,这样的情况下如果是批数据,倒是可以很好的解决(重新将这份固定的数据再执行一遍),但是流数据那就麻烦了,你根本不知道什么在 Job 挂的那个时刻数据消费到哪里了?那么你重启的话该从哪里开始重新消费呢?你可以有以下选择(因为你可能也不确定 Job 挂的具体时间):
- Job 挂的那个时间之前:如果是从 Job 挂之前开始重新消费的话,那么会导致部分数据(从新消费的时间点到之前 Job 挂的那个时间点之前的数据)重复消费
- Job 挂的那个时间之后:如果是从 Job 挂之后开始消费的话,那么会导致部分数据(从 Job 挂的那个时间点到新消费的时间点产生的数据)丢失,没有消费
上面两种情况用图片描述如下图所示。
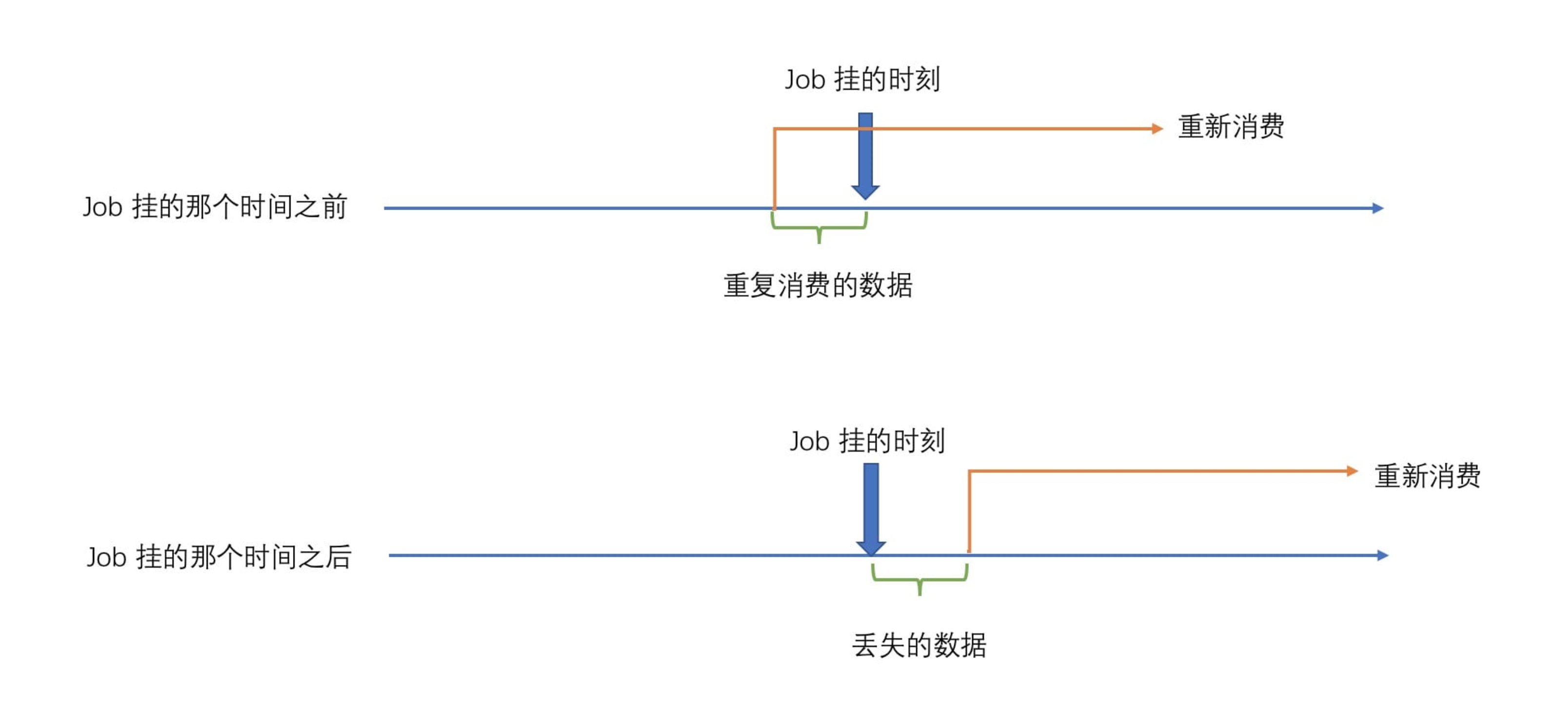
为了解决上面两种情况(数据重复消费或者数据没有消费)的发生,那么是不是就得需要个什么东西做个记录将这种数据消费状态,Flink state 就这样诞生了,state 中存储着每条数据消费后数据的消费点(生产环境需要持久化这些状态),当 Job 因为某种错误或者其他原因导致重启时,就能够从 Checkpoint(定时将 state 做一个全局快照,在 Flink 中,为了能够让 Job 在运行的过程中保证容错性,才会对这些 state 做一个快照,在 4.3 节中会详细讲) 中的 state 数据进行恢复。
4.1.2 State 的种类
在 Flink 中有两个基本的 state:Keyed state 和 Operator state,下面来分别介绍一下这两种 State。
4.1.3 Keyed State
Keyed State 总是和具体的 key 相关联,也只能在 KeyedStream 的 function 和 operator 上使用。你可以将 Keyed State 当作是 Operator State 的一种特例,但是它是被分区或分片的。每个 Keyed State 分区对应一个 key 的 Operator State,对于某个 key 在某个分区上有唯一的状态。逻辑上,Keyed State 总是对应着一个
4.1.4 Operator State
对 Operator State 而言,每个 operator state 都对应着一个并行实例。Kafka Connector 就是一个很好的例子。每个 Kafka consumer 的并行实例都会持有一份topic partition 和 offset 的 map,这个 map 就是它的 Operator State。
当并行度发生变化时,Operator State 可以将状态在所有的并行实例中进行重分配,并且提供了多种方式来进行重分配。
在 Flink 源码中,在 flink-core module 下的 org.apache.flink.api.common.state 中可以看到 Flink 中所有和 State 相关的类,如下图所示。
4.1.5 Raw State 和 Managed State
Keyed State 和 Operator State 都有两种存在形式,即 Raw State(原始状态)和 Managed State(托管状态)。
原始状态是 Operator(算子)保存它们自己的数据结构中的 state,当 Checkpoint 时,原始状态会以字节流的形式写入进 Checkpoint 中。Flink 并不知道 State 的数据结构长啥样,仅能看到原生的字节数组。
托管状态可以使用 Flink runtime 提供的数据结构来表示,例如内部哈希表或者 RocksDB。具体有 ValueState,ListState 等。Flink runtime 会对这些状态进行编码然后将它们写入到 Checkpoint 中。
DataStream 的所有 function 都可以使用托管状态,但是原生状态只能在实现 operator 的时候使用。相对于原生状态,推荐使用托管状态,因为如果使用托管状态,当并行度发生改变时,Flink 可以自动的帮你重分配 state,同时还可以更好的管理内存。
注意:如果你的托管状态需要特殊的序列化,目前 Flink 还不支持。
4.1.6 如何使用托管的 Keyed State
托管的 Keyed State 接口提供对不同类型状态(这些状态的范围都是当前输入元素的 key)的访问,这意味着这种状态只能在通过 stream.keyBy() 创建的 KeyedStream 上使用。
我们首先来看一下有哪些可以使用的状态,然后再来看看它们在程序中是如何使用的:
- ValueState
: 保存一个可以更新和获取的值(每个 Key 一个 value),可以用 update(T) 来更新 value,可以用 value() 来获取 value。 - ListState
: 保存一个值的列表,用 add(T) 或者 addAll(List ) 来添加,用 Iterable get() 来获取。 - ReducingState
: 保存一个值,这个值是状态的很多值的聚合结果,接口和 ListState 类似,但是可以用相应的 ReduceFunction 来聚合。 - AggregatingState
- FoldingState
- MapState
所有类型的状态都有一个 clear() 方法来清除当前的状态。
注意:FoldingState 已经不推荐使用,可以用 AggregatingState 来代替。
需要注意,上面的这些状态对象仅用来和状态打交道,状态不一定保存在内存中,也可以存储在磁盘或者其他地方。另外,你获取到的状态的值是取决于输入元素的 key,因此如果 key 不同,那么在一次调用用户函数中获得的值可能与另一次调用的值不同。
要使用一个状态对象,需要先创建一个 StateDescriptor,它包含了状态的名字(你可以创建若干个 state,但是它们必须要有唯一的值以便能够引用它们),状态的值的类型,或许还有一个用户定义的函数,比如 ReduceFunction。根据你想要使用的 state 类型,你可以创建 ValueStateDescriptor、ListStateDescriptor、ReducingStateDescriptor、FoldingStateDescriptor 或者 MapStateDescriptor。
状态只能通过 RuntimeContext 来获取,所以只能在 RichFunction 里面使用。RichFunction 中你可以通过 RuntimeContext 用下述方法获取状态:
- ValueState
getState(ValueStateDescriptor ) - ReducingState
getReducingState(ReducingStateDescriptor ) - ListState
getListState(ListStateDescriptor ) - AggregatingState
- FoldingState
- MapState
上面讲了这么多概念,那么来一个例子来看看如何使用状态:
1 | public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> { |
这个例子实现了一个简单的计数器,我们使用元组的第一个字段来进行分组(这个例子中,所有的 key 都是 1),这个 CountWindowAverage 函数将计数和运行时总和保存在一个 ValueState 中,一旦计数等于 2,就会发出平均值并清理 state,因此又从 0 开始。请注意,如果在第一个字段中具有不同值的元组,则这将为每个不同的输入 key保存不同的 state 值。
4.1.7 State TTL(存活时间)
随着作业的运行时间变长,作业的状态也会逐渐的变大,那么很有可能就会影响作业的稳定性,这时如果有状态的过期这种功能就可以将历史的一些状态清除,对应在 Flink 中的就是 State TTL,接下来将对其做详细介绍。
State TTL 介绍
TTL 可以分配给任何类型的 Keyed state,如果一个状态设置了 TTL,那么当状态过期时,那么之前存储的状态值会被清除。所有的状态集合类型都支持单个入口的 TTL,这意味着 List 集合元素和 Map 集合都支持独立到期。为了使用状态 TTL,首先必须要构建 StateTtlConfig 配置对象,然后可以通过传递配置在 State descriptor 中启用 TTL 功能:
1 | import org.apache.flink.api.common.state.StateTtlConfig; |
上面配置中有几个选项需要注意:
1、newBuilder 方法的第一个参数是必需的,它代表着状态存活时间。
2、UpdateType 配置状态 TTL 更新时(默认为 OnCreateAndWrite):
- StateTtlConfig.UpdateType.OnCreateAndWrite: 仅限创建和写入访问时更新
- StateTtlConfig.UpdateType.OnReadAndWrite: 除了创建和写入访问,还支持在读取时更新
3、StateVisibility 配置是否在读取访问时返回过期值(如果尚未清除),默认是 NeverReturnExpired:
- StateTtlConfig.StateVisibility.NeverReturnExpired: 永远不会返回过期值
- StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp: 如果仍然可用则返回
在 NeverReturnExpired 的情况下,过期状态表现得好像它不再存在,即使它仍然必须被删除。该选项对于在 TTL 之后必须严格用于读取访问的数据的用例是有用的,例如,应用程序使用隐私敏感数据.
另一个选项 ReturnExpiredIfNotCleanedUp 允许在清理之前返回过期状态。
注意:
- 状态后端会存储上次修改的时间戳以及对应的值,这意味着启用此功能会增加状态存储的消耗,堆状态后端存储一个额外的 Java 对象,其中包含对用户状态对象的引用和内存中原始的 long 值。RocksDB 状态后端存储为每个存储值、List、Map 都添加 8 个字节。
- 目前仅支持参考 processing time 的 TTL
- 使用启用 TTL 的描述符去尝试恢复先前未使用 TTL 配置的状态可能会导致兼容性失败或者 StateMigrationException 异常。
- TTL 配置并不是 Checkpoint 和 Savepoint 的一部分,而是 Flink 如何在当前运行的 Job 中处理它的方式。
- 只有当用户值序列化器可以处理 null 值时,具体 TTL 的 Map 状态当前才支持 null 值,如果序列化器不支持 null 值,则可以使用 NullableSerializer 来包装它(代价是需要一个额外的字节)。
清除过期 State
默认情况下,过期值只有在显式读出时才会被删除,例如通过调用 ValueState.value()。
注意:这意味着默认情况下,如果未读取过期状态,则不会删除它,这可能导致状态不断增长,这个特性在 Flink 未来的版本可能会发生变化。
此外,你可以在获取完整状态快照时激活清理状态,这样就可以减少状态的大小。在当前实现下不清除本地状态,但是在从上一个快照恢复的情况下,它不会包括已删除的过期状态,你可以在 StateTtlConfig 中这样配置:
1 | import org.apache.flink.api.common.state.StateTtlConfig; |
此配置不适用于 RocksDB 状态后端中的增量 Checkpoint。对于现有的 Job,可以在 StateTtlConfig 中随时激活或停用此清理策略,例如,从保存点重启后。
除了在完整快照中清理外,你还可以在后台激活清理。如果使用的后端支持以下选项,则会激活 StateTtlConfig 中的默认后台清理:
1 | import org.apache.flink.api.common.state.StateTtlConfig; |
要在后台对某些特殊清理进行更精细的控制,可以按照下面的说明单独配置它。目前,堆状态后端依赖于增量清理,RocksDB 后端使用压缩过滤器进行后台清理。
我们再来看看 TTL 对应着的类 StateTtlConfig 类中的具体实现,这样我们才能更加的理解其使用方式。
在该类中的属性如下图所示:
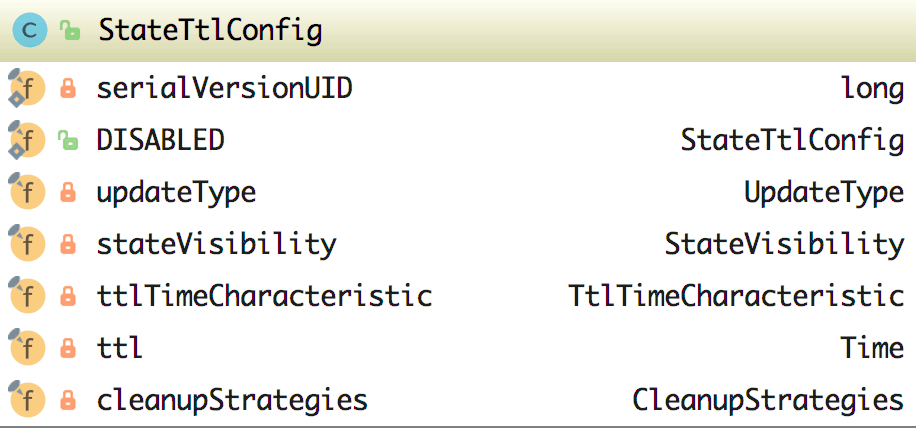
这些属性的功能如下:
- DISABLED:它默认创建了一个 UpdateType 为 Disabled 的 StateTtlConfig
- UpdateType:这个是一个枚举,包含 Disabled(代表 TTL 是禁用的,状态不会过期)、OnCreateAndWrite、OnReadAndWrite 可选
- StateVisibility:这也是一个枚举,包含了 ReturnExpiredIfNotCleanedUp、NeverReturnExpired
- TimeCharacteristic:这是时间特征,其实是只有 ProcessingTime 可选
- Time:设置 TTL 的时间,这里有两个参数 unit 和 size
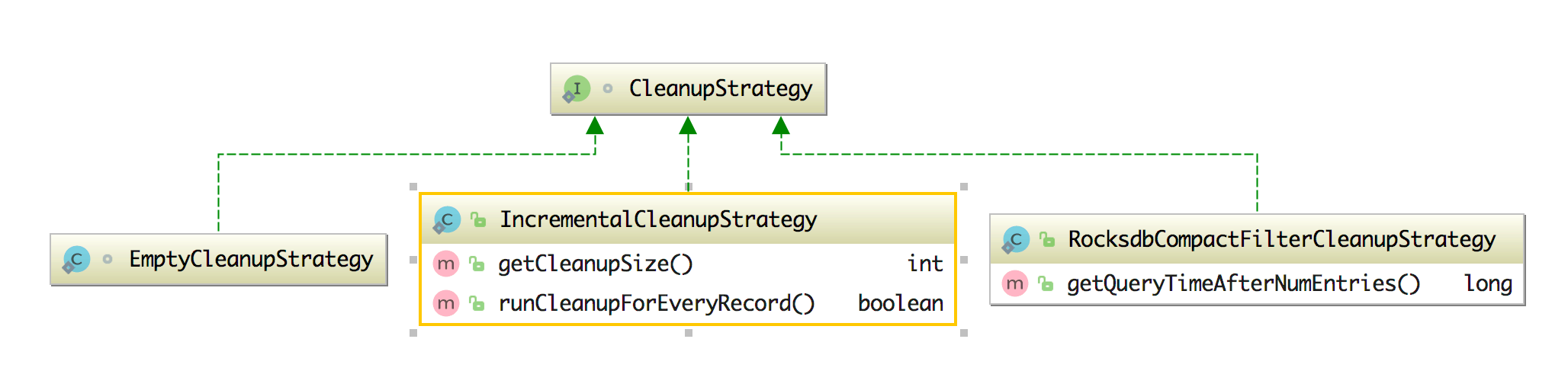
- CleanupStrategies:TTL 清理策略,在该类中有字段 isCleanupInBackground(是否在后台清理) 和相关的清理 strategies(包含 FULL_STATE_SCAN_SNAPSHOT、INCREMENTAL_CLEANUP 和 ROCKSDB_COMPACTION_FILTER),同时该类中还有 CleanupStrategy 接口,它的实现类有 EmptyCleanupStrategy(不清理,为空)、IncrementalCleanupStrategy(增量的清除)、RocksdbCompactFilterCleanupStrategy(在 RocksDB 中自定义压缩过滤器),该类和其实现类如下图所示。
如果对 State TTL 还有不清楚的可以看看 Flink 源码 flink-runtime module 中的 state ttl 相关的实现类,如下图所示:

4.1.8 如何使用托管的 Operator State
CheckpointedFunction
ListCheckpointed
4.1.9 Stateful Source Functions
4.1.10 Broadcast State
Flink 中的 Broadcast State 在很多场景下也有使用,下面来讲解下其使用方式。
Broadcast State 如何使用
使用 Broadcast state 需要注意
4.1.11 Queryable State
加入知识星球可以看到上面文章: https://t.zsxq.com/ZVByvzN

4.1.12 小结与反思
本节一开始讲解了 State 出现的原因,接着讲解了 Flink 中的 State 分类,然后对 Flink 中的每种 State 做了详细的讲解,希望可以好好消化这节的内容。你对本节的内容有什么不理解的地方吗?在使用 State 的过程中有遇到什么问题吗?


