
4.3 Flink Checkpoint 和 Savepoint 的区别及其配置使用
Checkpoint 在 Flink 中是一个非常重要的 Feature,Checkpoint 使 Flink 的状态具有良好的容错性,通过 Checkpoint 机制,Flink 可以对作业的状态和计算位置进行恢复。本节主要讲述在 Flink 中 Checkpoint 和 Savepoint 的使用方式及它们之间的区别。
4.3.1 Checkpoint 简介及使用
在 Flink 任务运行过程中,为了保障故障容错,Flink 需要对状态进行快照。Flink 可以从 Checkpoint 中恢复流的状态和位置,从而使得应用程序发生故障后能够得到与无故障执行相同的语义。
Flink 的 Checkpoint 有以下先决条件:
- 需要具有持久性且支持重放一定时间范围内数据的数据源。例如:Kafka、RabbitMQ 等。这里为什么要求支持重放一定时间范围内的数据呢?因为 Flink 的容错机制决定了,当 Flink 任务失败后会自动从最近一次成功的 Checkpoint 处恢复任务,此时可能需要把任务失败前消费的部分数据再消费一遍,所以必须要求数据源支持重放。假如一个Flink 任务消费 Kafka 并将数据写入到 MySQL 中,任务从 Kafka 读取到数据,还未将数据输出到 MySQL 时任务突然失败了,此时如果 Kafka 不支持重放,就会造成这部分数据永远丢失了。支持重放数据的数据源可以保障任务消费失败后,能够重新消费来保障任务不丢数据。
- 需要一个能保存状态的持久化存储介质,例如:HDFS、S3 等。当 Flink 任务失败后,自动从 Checkpoint 处恢复,但是如果 Checkpoint 时保存的状态信息快照全丢了,那就会影响 Flink 任务的正常恢复。就好比我们看书时经常使用书签来记录当前看到的页码,当下次看书时找到书签的位置继续阅读即可,但是如果书签三天两头经常丢,那我们就无法通过书签来恢复阅读。
Flink 中 Checkpoint 是默认关闭的,对于需要保障 At Least Once 和 Exactly Once 语义的任务,强烈建议开启 Checkpoint,对于丢一小部分数据不敏感的任务,可以不开启 Checkpoint,例如:一些推荐相关的任务丢一小部分数据并不会影响推荐效果。下面来介绍 Checkpoint 具体如何使用。
首先调用 StreamExecutionEnvironment 的方法 enableCheckpointing(n) 来开启 Checkpoint,参数 n 以毫秒为单位表示 Checkpoint 的时间间隔。Checkpoint 配置相关的 Java 代码如下所示:
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutinEnvironment(); |
以上 Checkpoint 相关的参数描述如下所示:
- Checkpoint 语义: EXACTLY_ONCE 或 AT_LEAST_ONCE,EXACTLY_ONCE 表示所有要消费的数据被恰好处理一次,即所有数据既不丢数据也不重复消费;AT_LEAST_ONCE 表示要消费的数据至少处理一次,可能会重复消费。
- Checkpoint 超时时间:如果 Checkpoint 时间超过了设定的超时时间,则 Checkpoint 将会被终止。
- 同时进行的 Checkpoint 数量:默认情况下,当一个 Checkpoint 在进行时,JobManager 将不会触发下一个 Checkpoint,但 Flink 允许多个 Checkpoint 同时在发生。
- 两次 Checkpoint 之间的最小时间间隔:从上一次 Checkpoint 结束到下一次 Checkpoint 开始,中间的间隔时间。例如,env.enableCheckpointing(60000) 表示 1 分钟触发一次 Checkpoint,同时再设置两次 Checkpoint 之间的最小时间间隔为 30 秒,假如任务运行过程中一次 Checkpoint 就用了50s,那么等 Checkpoint 结束后,理论来讲再过 10s 就要开始下一次 Checkpoint 了,但是由于设置了最小时间间隔为30s,所以需要再过 30s 后,下次 Checkpoint 才开始。注:如果配置了该参数就决定了同时进行的 Checkpoint 数量只能为 1。
- 当任务被取消时,外部 Checkpoint 信息是否被清理:Checkpoint 在默认的情况下仅用于恢复运行失败的 Flink 任务,当任务手动取消时 Checkpoint 产生的状态信息并不保留。当然可以通过该配置来保留外部的 Checkpoint 状态信息,这些被保留的状态信息在作业手动取消时不会被清除,这样就可以使用该状态信息来恢复 Flink 任务,对于需要从状态恢复的任务强烈建议配置为外部 Checkpoint 状态信息不清理。可选择的配置项为:
- ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:当作业手动取消时,保留作业的 Checkpoint 状态信息。注意,这种情况下,需要手动清除该作业保留的 Checkpoint 状态信息,否则这些状态信息将永远保留在外部的持久化存储中。
- ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:当作业取消时,Checkpoint 状态信息会被删除。仅当作业失败时,作业的 Checkpoint 才会被保留用于任务恢复。
任务失败,当有较新的 Savepoint 时,作业是否回退到 Checkpoint 进行恢复:默认情况下,当 Savepoint 比 Checkpoint 较新时,任务会从 Savepoint 处恢复。
作业可以容忍 Checkpoint 失败的次数:默认值为 0,表示不能接受 Checkpoint 失败。
关于 Checkpoint 时,状态后端相关的配置请参阅本书 4.2 节。
4.3.2 Savepoint 简介及使用
Savepoint 与 Checkpoint 类似,同样需要把状态信息存储到外部介质,当作业失败时,可以从外部存储中恢复。强烈建议在程序中给算子分配 Operator ID,以便来升级程序。主要通过 uid(String) 方法手动指定算子的 ID ,这些 ID 将用于恢复每个算子的状态。
1 | DataStream<String> stream = env. |
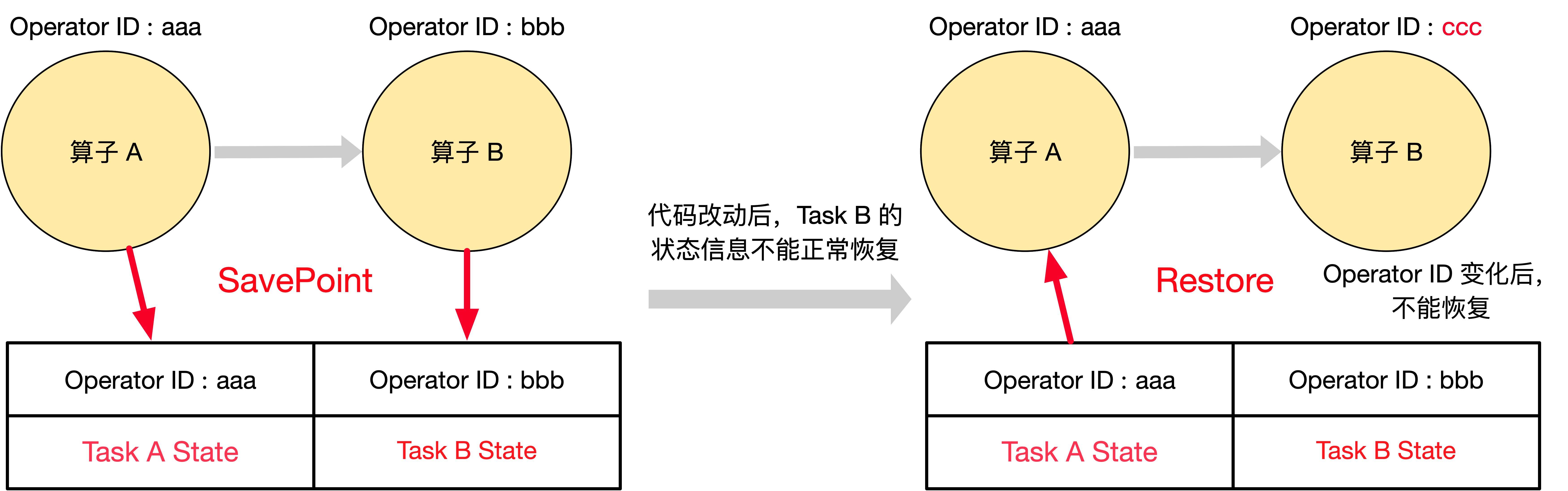
如果不为算子手动指定 ID,Flink 会为算子自动生成 ID。当 Flink 任务从 Savepoint 中恢复时,是按照 Operator ID 将快照信息与算子进行匹配的,只要这些 ID 不变,Flink 任务就可以从 Savepoint 中恢复。自动生成的 ID 取决于代码的结构,并且对代码更改比较敏感,因此强烈建议给程序中所有有状态的算子手动分配 Operator ID。如下图所示,一个 Flink 任务包含了 算子 A 和 算子 B,代码中都未指定 Operator ID,所以 Flink 为 Task A 自动生成了 Operator ID 为 aaa,为 Task B 自动生成了 Operator ID 为 bbb,且 Savepoint 成功完成。但是在代码改动后,任务并不能从 Savepoint 中正常恢复,因为 Flink 为算子生成的 Operator ID 取决于代码结构,代码改动后可能会把算子 B 的 Operator ID 改变成 ccc,导致任务从 Savepoint 恢复时,SavePoint 中只有 Operator ID 为 aaa 和 bbb 的状态信息,算子 B 找不到 Operator ID 为 ccc 的状态信息,所以算子 B 不能正常恢复。这里如果在写代码时通过 uid(String) 手动指定了 Operator ID,就不会存在 上述问题了。
Savepoint 需要用户手动去触发,触发 Savepoint 的方式如下所示:
1 | bin/flink savepoint :jobId [:targetDirectory] |
这将触发 ID 为 :jobId 的作业进行 Savepoint,并返回创建的 Savepoint 路径,用户需要此路径来还原和删除 Savepoint 。
使用 YARN 触发 Savepoint 的方式如下所示:
1 | bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId |
这将触发 ID 为 :jobId 和 YARN 应用程序 ID :yarnAppId 的作业进行 Savepoint,并返回创建的 Savepoint 路径。
使用 Savepoint 取消 Flink 任务:
1 | bin/flink cancel -s [:targetDirectory] :jobId |
这将自动触发 ID 为 :jobid 的作业进行 Savepoint,并在 Checkpoint 结束后取消该任务。此外,可以指定一个目标文件系统目录来存储 Savepoint 的状态信息,也可以在 flink 的 conf 目录下 flink-conf.yaml 中配置 state.savepoints.dir 参数来指定 Savepoint 的默认目录,触发 Savepoint 时,如果不指定目录则使用该默认目录。无论使用哪种方式配置,都需要保障配置的目录能被所有的 JobManager 和 TaskManager 访问。
4.3.3 Savepoint 与 Checkpoint 的区别
前面分别介绍了 Savepoint 和 Checkpoint,可以发现它们有不少相似之处,下面来看下它们之间的区别。
| Checkpoint | Savepoint |
|---|---|
| 由 Flink 的 JobManager 定时自动触发并管理 | 由用户手动触发并管理 |
| 主要用于任务发生故障时,为任务提供给自动恢复机制 | 主要用户升级 Flink 版本、修改任务的逻辑代码、调整算子的并行度,且必须手动恢复 |
| 当使用 RocksDBStateBackend 时,支持增量方式对状态信息进行快照 | 仅支持全量快照 |
| Flink 任务停止后,Checkpoint 的状态快照信息默认被清除 | 一旦触发 Savepoint,状态信息就被持久化到外部存储,除非用户手动删除 |
| Checkpoint 设计目标:轻量级且尽可能快地恢复任务 | Savepoint 的生成和恢复成本会更高一些,Savepoint 更多地关注代码的可移植性和兼容任务的更改操作 |
4.3.4 Checkpoint 流程
Flink 任务 Checkpoint 的详细流程如下面流程所示。
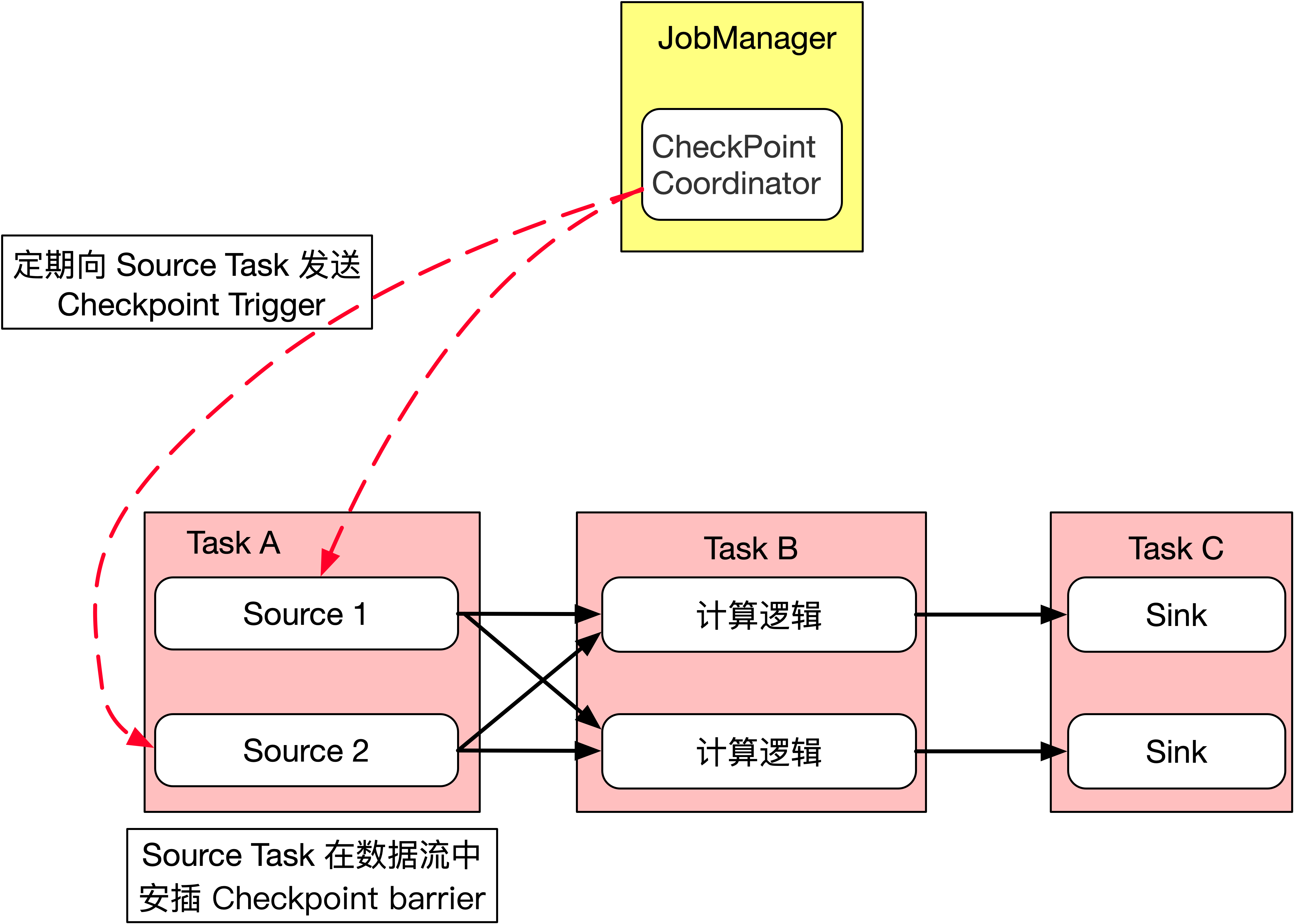
JobManager 端的 CheckPointCoordinator 会定期向所有 SourceTask 发送 CheckPointTrigger,Source Task 会在数据流中安插 Checkpoint barrier,如下图所示。
当 task 收到上游所有实例的 barrier 后,向自己的下游继续传递 barrier,然后自身同步进行快照,并将自己的状态异步写入到持久化存储中,如下图所示。
- 如果是增量 Checkpoint,则只是把最新的一部分更新写入到外部持久化存储中
- 为了下游尽快进行 Checkpoint,所以 task 会先发送 barrier 到下游,自身再同步进行快照
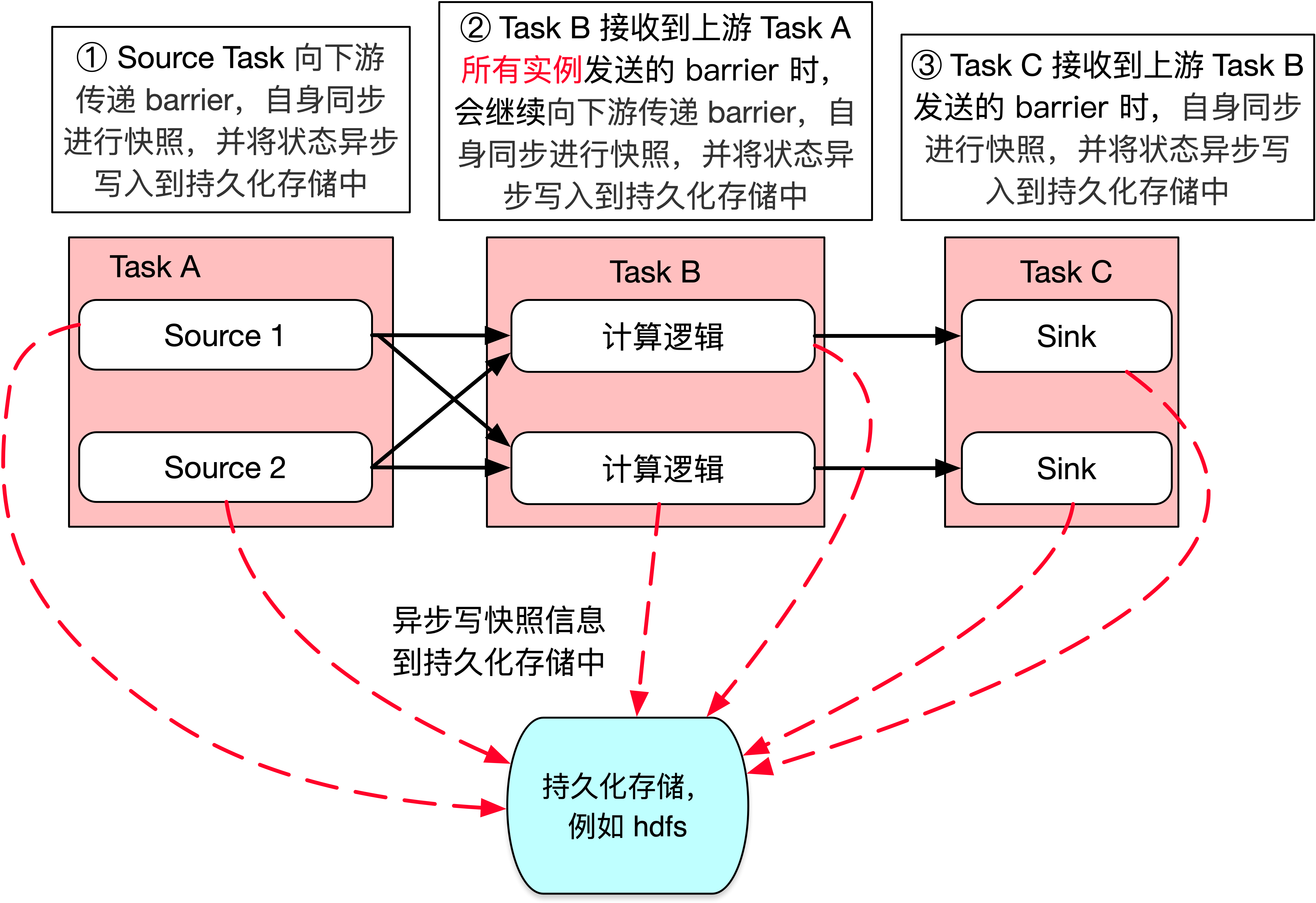
注:Task B 必须接收到上游 Task A 所有实例发送的 barrier 时,Task B 才能开始进行快照,这里有一个 barrier 对齐的概念,关于 barrier 对齐的详细介绍请参阅 9.5.1 节 Flink 内部如何保证 Exactly Once 中的 barrier 对齐部分
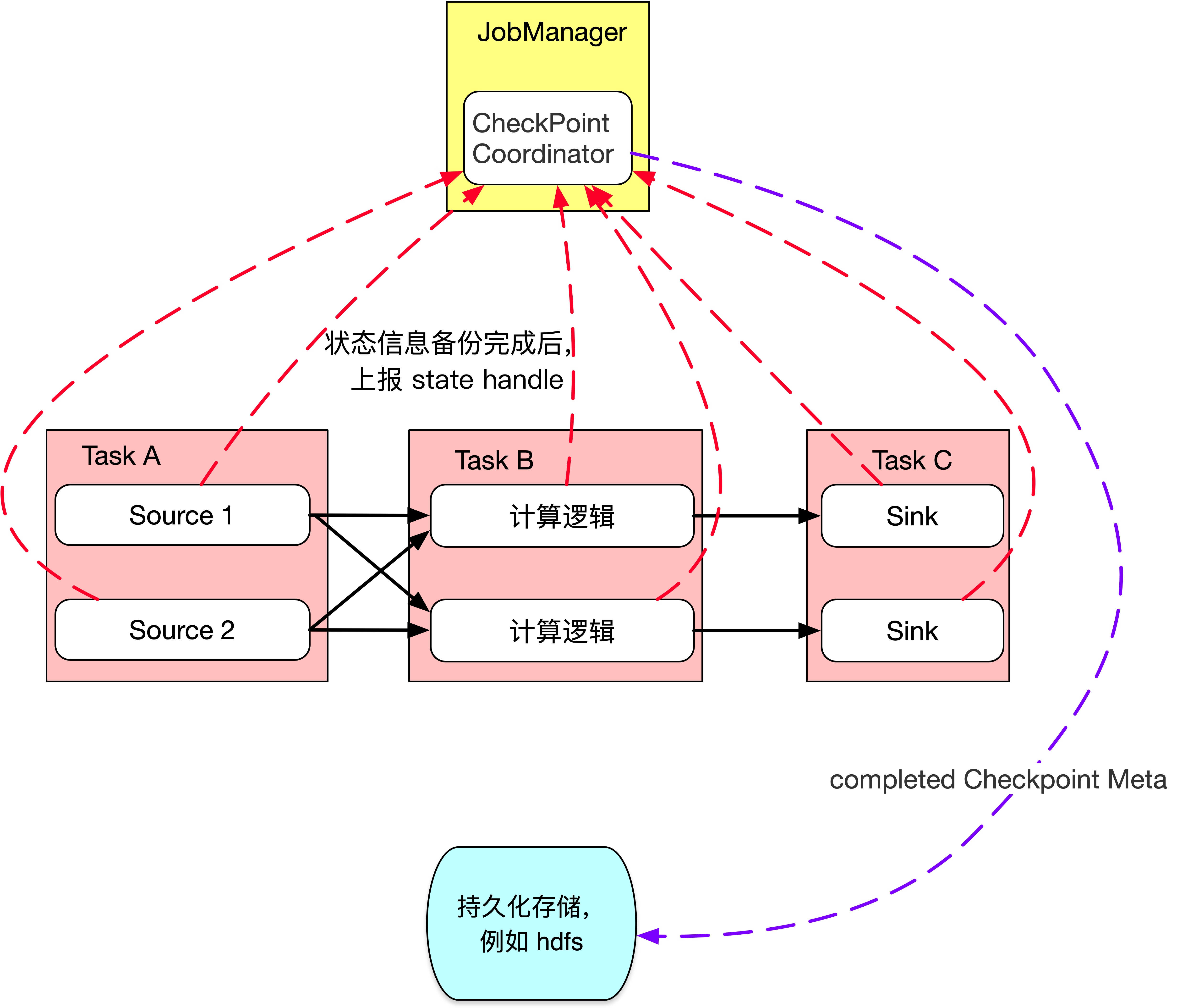
当 task 将状态信息完成备份后,会将备份数据的地址(state handle)通知给 JobManager 的CheckPointCoordinator,如果 Checkpoint 的持续时长超过了 Checkpoint 设定的超时时间CheckPointCoordinator 还没有收集完所有的 State Handle,CheckPointCoordinator 就会认为本次 Checkpoint 失败,会把这次 Checkpoint 产生的所有状态数据全部删除
如果 CheckPointCoordinator 收集完所有算子的 State Handle,CheckPointCoordinator 会把整个 StateHandle 封装成 completed Checkpoint Meta,写入到外部存储中,Checkpoint 结束,如下图所示。
如果对上述 Checkpoint 过程不理解,在后续 9.5 节 Flink 如何保障 Exactly Once 中会详细介绍 Flink 的 Checkpoint 过程以及为什么这么做。
基于 RocksDB 的增量 Checkpoint 实现原理
当使用 RocksDBStateBackend 时,增量 Checkpoint 是如何实现的呢?RocksDB 是一个基于 LSM 实现的 KV 数据库。LSM 全称 Log Structured Merge Trees,LSM 树本质是将大量的磁盘随机写操作转换成磁盘的批量写操作来极大地提升磁盘数据写入效率。一般 LSM Tree 实现上都会有一个基于内存的 MemTable 介质,所有的增删改操作都是写入到 MemTable 中,当 MemTable 足够大以后,将 MemTable 中的数据 flush 到磁盘中生成不可变且内部有序的 ssTable(Sorted String Table)文件,全量数据保存在磁盘的多个 ssTable 文件中。HBase 也是基于 LSM Tree 实现的,HBase 磁盘上的 HFile 就相当于这里的 ssTable 文件,每次生成的 HFile 都是不可变的而且内部有序的文件。基于 ssTable 不可变的特性,才实现了增量 Checkpoint,具体流程如下图所示。
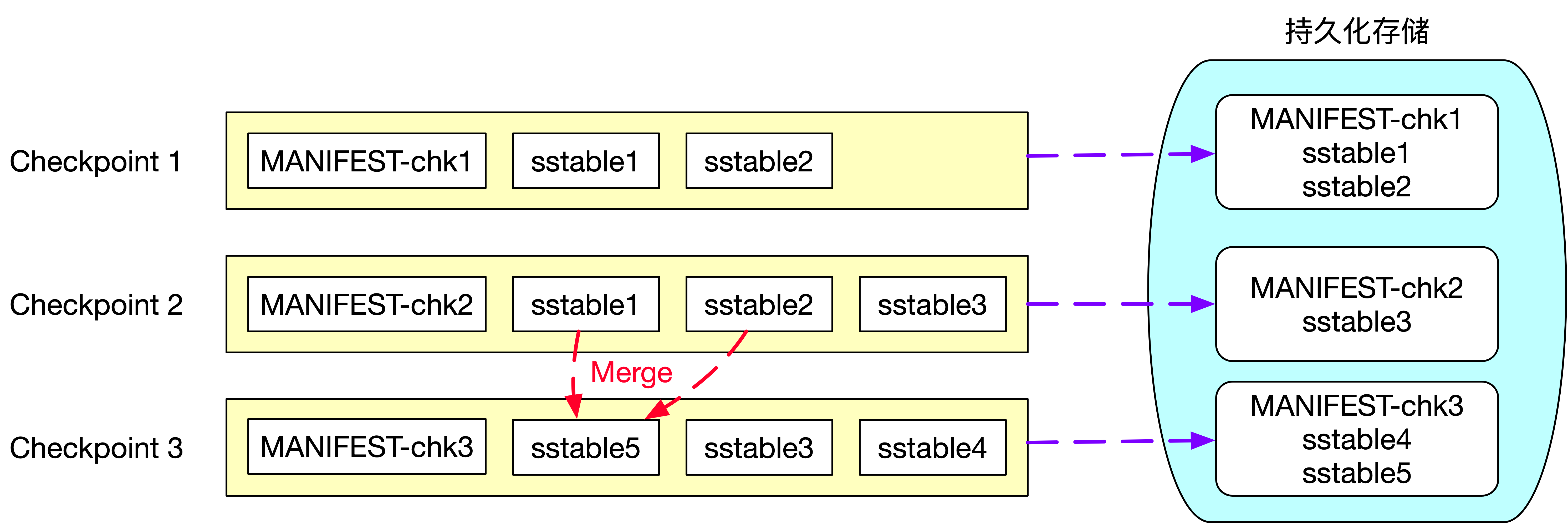
第一次 Checkpoint 时生成的状态快照信息包含了两个 sstable 文件:sstable1 和 sstable2 及 Checkpoint1 的元数据文件 MANIFEST-chk1,所以第一次 Checkpoint 时需要将 sstable1、sstable2 和 MANIFEST-chk1 上传到外部持久化存储中。第二次 Checkpoint 时生成的快照信息为 sstable1、sstable2、sstable3 及元数据文件 MANIFEST-chk2,由于 sstable 文件的不可变特性,所以状态快照信息的 sstable1、sstable2 这两个文件并没有发生变化,sstable1、sstable2 这两个文件不需要重复上传到外部持久化存储中,因此第二次 Checkpoint 时,只需要将 sstable3 和 MANIFEST-chk2 文件上传到外部持久化存储中即可。这里只将新增的文件上传到外部持久化存储,也就是所谓的增量 Checkpoint。
基于 LSM Tree 实现的数据库为了提高查询效率,都需要定期对磁盘上多个 sstable 文件进行合并操作,合并时会将删除的、过期的以及旧版本的数据进行清理,从而降低 sstable 文件的总大小。图中可以看到第三次 Checkpoint 时生成的快照信息为sstable3、sstable4、sstable5 及元数据文件 MANIFEST-chk3, 其中新增了 sstable4 文件且 sstable1 和 sstable2 文件合并成 sstable5 文件,因此第三次 Checkpoint 时只需要向外部持久化存储上传 sstable4、sstable5 及元数据文件 MANIFEST-chk3。
基于 RocksDB 的增量 Checkpoint 从本质上来讲每次 Checkpoint 时只将本次 Checkpoint 新增的快照信息上传到外部的持久化存储中,依靠的是 LSM Tree 中 sstable 文件不可变的特性。对 LSM Tree 感兴趣的同学可以深入研究 RocksDB 或 HBase 相关原理及实现。
4.3.5 如何从 Checkpoint 中恢复状态
4.3.6 如何从 Savepoint 中恢复状态
4.3.7 如何优雅地删除 Checkpoint 目录
4.3.8 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RNJeqFy

本章属于属于本书的进阶篇,在第一节中讲解了 State 的各种类型,包括每种 State 的使用方式、实现原理和部分源码剖析,在第二节中介绍 Flink 中的状态后端存储的使用方式,对比分析了现有的几种方案的使用场景,在第三节中介绍了 Checkpoint 和 Savepoint 的区别,如果从状态中恢复作业,以及整个作业的 Checkpoint 流程。
本章的内容是 Flink 作业开发的重点,通常线上遇到 State、Checkpoint、Savepoint 的问题比较多,所以希望你能好好的弄清楚它们的原理,这样在出问题后才能够对症下药去解决问题。


