
12.2 基于 Flink 的百亿数据去重实践
在工作中经常会遇到去重的场景,例如基于 APP 的用户行为日志分析系统:用户的行为日志从手机 APP 端上报到 Nginx 服务端,然后通过 Logstash、Flume 或其他工具将日志从 Nginx 写入到 Kafka 中。由于用户手机客户端的网络可能出现不稳定,所以手机 APP 端上传日志的策略是:宁可重复上报,也不能漏报日志,所以导致 Kafka 中可能会出现日志重复的情况,即:同一条日志出现了 2 条或 2 条以上。通常情况下,Flink 任务的数据源都是 Kafka,若 Kafka 中数据出现了重复,在实时 ETL 或者流计算时都需要考虑基于日志主键对日志进行去重,否则会导致流计算结果偏高或结果不准确的问题,例如用户 a 在某个页面只点击了一次,但由于日志重复上报,所以用户 a 在该页面的点击日志在 Kafka 中出现了 2 次,最后统计该页面的点击数时,结果就会偏高。这里只阐述了一种可能造成 Kafka 中数据重复的情况,在生产环境中很多情况都可能造成 Kafka 中数据重复,这里不一一列举,本节主要讲述出现了数据重复后,该如何处理。
12.2.1 去重的通用解决方案
Kafka 中数据出现重复后,各种解决方案都比较类似,一般需要一个全局 Set 集合来维护历史所有数据的主键。当处理新日志时,需要拿到当前日志的主键与历史数据的 Set 集合按照规则进行比较,若 Set 集合中已经包含了当前日志的主键,说明当前日志在之前已经被处理过了,则当前日志应该被过滤掉,否则认为当前日志不应该被过滤应该被处理,而且处理完成后需要将新日志的主键加入到 Set 集合中,Set 集合永远存放着所有已经被处理过的数据。这种去重的通用解决方案的流程图如下图所示。
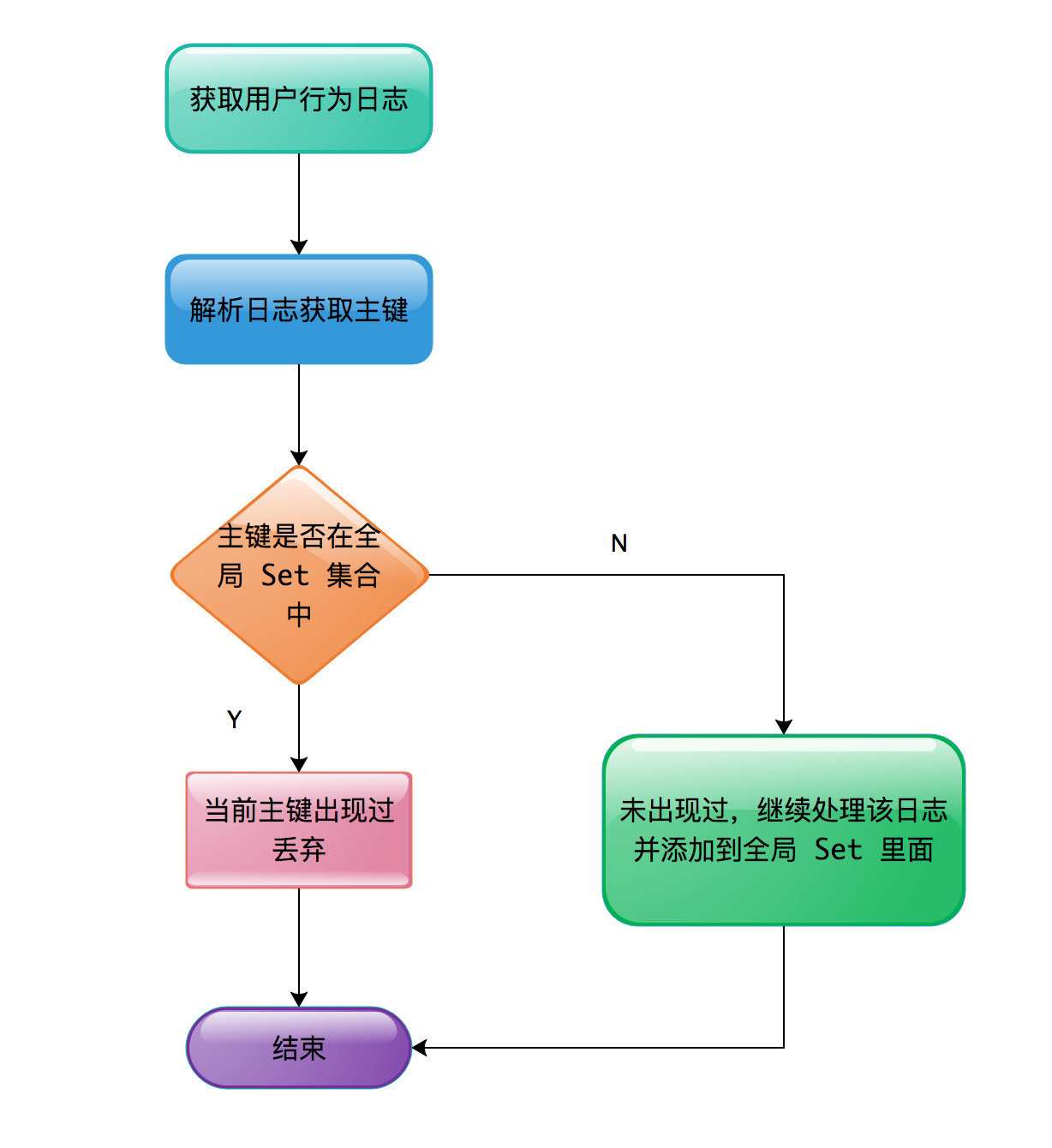
处理流程很简单,关键在于如何维护这个 Set 集合,可以简单估算一下这个 Set 集合需要占用多大空间。本小节要解决的问题是百亿数据去重,所以就按照每天 1 百亿的数据量来计算。由于每天数据量巨大,因此主键占用空间通常会比较大,如果主键占用空间小意味着表示的数据范围就比较小,就可能导致主键冲突,例如:4 个字节的 int 类型表示数据范围是为 -2147483648 ~ 2147483647,总共可以表示 42 亿个数,如果这里每天百亿的数据量选用 int 类型做为主键的话,很明显会有大量的主键发生冲突,会将不重复的数据认为是发生了重复。用户的行为日志是在手机客户端生成的,没有全局发号器,一般会选取 UUID 做为日志的主键,UUID 会生成 36 位的字符串,例如:”f106c4a1-4c6f-41c1-9d30-bbb2b271284a”。每个主键占用 36 字节,每天 1 百亿数据,36字节 100亿 ≈ 360 GB。这仅仅是一天的数据量,所以该 Set 集合要想存储空间不发生持续地爆炸式增长,必须增加一个功能,那就是给所有的主键增加 TTL(过期时间)。如果不增加 TTL,10 天数据量的主键占用空间就 3.6T,100 天数据量的主键占用空间 36T,所以在设计之初必须考虑为主键设定 TTL。如果要求按天进行去重或者认为日志发生重复上报的时间间隔不可能大于 24 小时,那么为了系统的可靠性 TTL 可以设置为 36 小时。每天数据量 1 百亿,且 Set 集合中存放着 36 小时的数据量,即 100 亿 1.5 = 150 亿,所以 Set 集合中需要维护 150 亿的数据量,且 Set 集合中每条数据都增加了 TTL,意味着 Set 集合需要为每条数据再附带保存一个时间戳,来确定该数据什么时候过期。例如 Redis 中为一个 key 设置了 TTL,如果没有为这个 key 附带时间戳,那么根本无法判断该 key 什么时候应该被清理。所以在考虑每条数据占用空间时,不仅要考虑数据本身,还需要考虑是否需要其他附带的存储。主键本身占用 36 字节加上 long 类型的时间戳 8 字节,所以每条数据至少需要占用 44 字节,150 亿 * 44 字节 = 660 GB。所以每天百亿的数据量,如果我们使用 Set 集合的方案来实现,至少需要占用 660 GB 以上的存储空间。
12.2.2 使用 BloomFilter 实现去重
有些流计算的场景对准确性要求并不是很高,例如传统的 Lambda 架构中,都会有离线去矫正实时计算的结果,所以根据业务场景,当业务要求可以接受结果有小量误差时,可以选择使用一些低成本的数据结构。BloomFilter 和 HyperLogLog 都是相对低成本的数据结构,分别有自己的应用场景,且两种数据结构都有一定误差。HyperLogLog 可以估算出 HyperLogLog 中插入了多少个不重复的元素,而不能告诉我们之前是否插入了哪些元素。BloomFilter 则恰好相反,相对而言 BloomFilter 更像是一个 Set 集合,BloomFilter 可以告诉你 BloomFilter 中肯定不包含元素 a,或者告诉你 BloomFilter 中可能包含元素 b,但 BloomFilter 不能告诉你 BloomFilter 中插入了多少个元素。接下来了解一下 BloomFilter 的实现原理。
bitmap 位图
了解 BloomFilter,从 bitmap(位图)开始说起。现在有 1 千万个整数,数据范围在 0 到 2 千万之间。如何快速查找某个整数是否在这 1 千万个整数中呢?可以将这 1 千万个数保存在 HashMap 中,不考虑对象头及其他空间,1000 万个 int 类型数据需要占用大约 1000万 * 4 字节 ≈ 40 MB 存储空间。有没有其他方案呢?因为数据范围是 0 到 2 千万,所以可以申请一个长度为 2000 万、boolean 类型的数组,将这 2 千万个整数作为数组下标,将其对应的数组默认值设置成 false,如下图所示,数组下标为 2、666、999 的位置存储的数据为 true,表示 1 千万个数中包含了 2、666、999 等。当查询某个整数 K 是否在这 1 千万个整数中时,只需要将对应的数组值 array[K] 取出来,看是否等于 true。如果等于 true,说明 1 千万整数中包含这个整数 K,否则表示不包含这个整数 K。

Java 的 boolean 基本类型占用一个字节(8bit)的内存空间,所以上述方案需要申请 2000 万字节。如下图所示,可以通过编程语言用二进制位来模拟布尔类型,二进制的 1 表示true、二进制的 0 表示false。通过二进制模拟布尔类型的方案,只需要申请 2000 万 bit 即可,相比 boolean 类型而言,存储空间占用仅为原来的 1/8。2000 万 bit ≈ 2.4 MB,相比存储原始数据的方案 40 MB 而言,占用的存储空间少了很多。

假如这 1 千万个整数的数据范围是 0 到 100 亿,那么就需要申请 100 亿个 bit 约等于 1200 MB,比存储原始数据方案的 40MB 还要大很多。该情况下,直接使用位图使用的存储空间更多了,怎么解决呢?可以只申请 1 亿 bit 的存储空间,对 1000 万个数求hash,映射到 1 亿的二进制位上,最后大约占用 12 MB 的存储空间,但是可能存在 hash 冲突的情况。例如 3 和 100000003(一亿零三)这两个数对一亿求余都为 3,所以映射到长度为 1 亿的位图上,这两个数会占用同一个 bit,就会导致一个问题:1 千万个整数中包含了一亿零三,所以位图中下标为 3 的位置存储着二进制 1。当查询 1 千万个整数中是否包含数字 3 时,同样也是去位图中下标 3 的位置去查找,发现下标为 3 的位置存储着二进制 1,所以误以为 1 千万个整数中包含数字 3。为了减少 hash 冲突,于是诞生了 BloomFilter。
BloomFilter 原理介绍
hash 存在 hash 冲突(碰撞)的问题,两个不同的 key 通过同一个 hash 函数得到的值有可能相同。为了减少冲突,可以引入多个 hash 函数,如果通过其中的一个 hash 函数发现某元素不在集合中,那么该元素肯定不在集合中。当所有的 hash 函数告诉我们该元素在集合中时,才能确定该元素存在于集合中,这便是BloomFilter的基本思想。
如下图所示,是往 BloomFilter 中插入元素 a、b 的过程,有 3 个 hash 函数,元素 a 经过 3 个 hash 函数后对应的 2、8、10 这三个二进制位,所以将这三个二进制位置为 1,元素 b 经过 3 个 hash 函数后,对应的 5、10、14 这三个二进制位,将这三个二进制位也置为 1,其中下标为 10 的二进制位被 a、b 元素都涉及到。

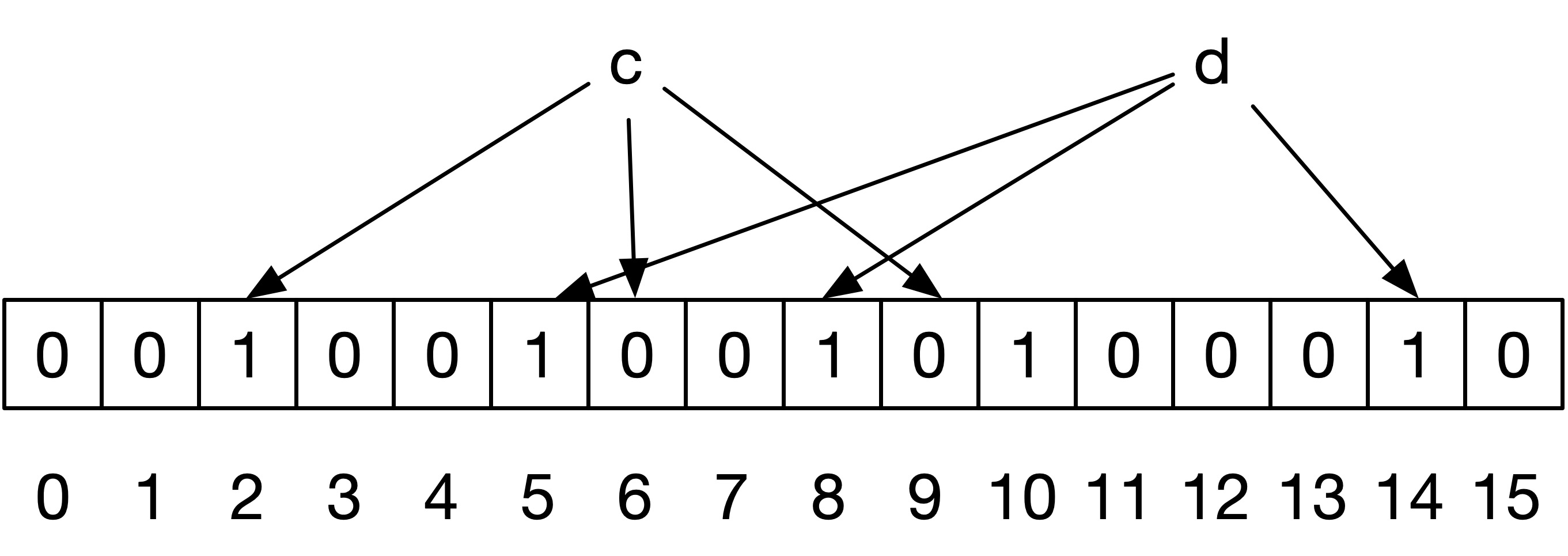
如下图所示,是从 BloomFilter 中查找元素 c、d 的过程,同样包含了 3 个 hash 函数,元素 c 经过 3 个 hash 函数后对应的 2、6、9 这三个二进制位,其中下标 6 和 9 对应的二进制位为 0,所以会认为 BloomFilter 中不存在元素 c。元素 d 经过 3 个 hash 函数后对应的 5、8、14 这三个二进制位,这三个位对应的二进制位都为 1,所以会认为 BloomFilter 中存在元素 d,但其实 BloomFilter 中并不存在元素 d,是因为元素 a 和元素 b 也对应到了 5、8、14 这三个二进制位上,所以 BloomFilter 会有误判。但是从实现原理来看,当 BloomFilter 告诉你不包含元素 c 时,BloomFilter 中肯定不包含元素 c,当 BloomFilter 告诉你 BloomFilter 中包含元素 d 时,它只是可能包含,也有可能不包含。
使用 BloomFilter 实现数据去重
Redis 4.0 之后 BloomFilter 以插件的形式加入到 Redis 中,关于 api 的具体使用这里不多赘述。BloomFilter 在创建时支持设定一个预期容量和误判率,预期容量即预计插入的数据量,误判率即:当 BloomFilter 中插入的数据达到预期容量时,误判的概率,如果 BloomFilter 中插入数据较少的话,误判率会更低。
经笔者测试,申请一个预期容量为 10 亿,误判率为千分之一的 BloomFilter,BloomFilter 会申请约 143 亿个 bit,即:14G左右,相比之前 660G 的存储空间小太多了。但是在使用过程中,需要记录 BloomFilter 中插入元素的个数,当插入元素个数达到 10 亿时,为了保障误差率,可以将当前 BloomFilter 清除,重新申请一个新的 BloomFilter。
通过使用 Redis 的 BloomFilter,我们可以通过相对较小的内存实现百亿数据的去重,但是 BloomFilter 有误差,所以只能使用在那些对结果能承受一定误差的应用场景,对于广告计费等对数据精度要求非常高的场景,极力推荐大家使用精准去重的方案来实现。
12.2.3 使用 HBase 维护全局 Set 实现去重
通过之前分析,我们知道要想实现百亿数据量的精准去重,需要维护 150 亿数据量的 Set 集合,每条数据占用 44 KB,总共需要 660 GB 的存储空间。注意这里说的是存储空间而不是内存空间,为什么呢?因为 660 G 的内存实在是太贵了,660G 的 Redis 云服务一个月至少要 2 万 RMB 以上,俗话说设计架构不考虑成本等于耍流氓。这里使用 Redis 确实可以解决问题,但是成本较高。HBase 基于 RowKey Get 的效率比较高,所以这里可以考虑将这个大的 Set 集合以 HBase RowKey 的形式存放到 HBase 中。HBase 表设置 TTL 为 36 小时,最近 36 小时的 150 亿条日志的主键都存放到 HBase 中,每来一条数据,先拿到主键去 HBase 中查询,如果 HBase 表中存在该主键,说明当前日志已经被处理过了,当前日志应该被过滤。如果 HBase 表中不存在该主键,说明当前日志之前没有被处理过,此时应该被处理,且处理完成后将当前主键 Put 到 HBase 表中。由于数据量比较大,所以一定要提前对 HBase 表进行预分区,将压力分散到各个 RegionServer 上。
使用 HBase RowKey 去重带来的问题
12.2.4 使用 Flink 的 KeyedState 实现去重
下面就教大家如何使用 Flink 的 KeyedState 实现去重。
使用 Flink 状态来维护 Set 集合的优势
如何使用 KeyedState 维护 Set 集合
优化主键来减少状态大小,且提高吞吐量
12.2.5 使用 RocksDBStateBackend 的优化方法
在使用上述方案的过程中,可能会出现吞吐量时高时低,或者吞吐量比笔者的测试性能要低一些,当出现这类问题的时候,可以尝试从以下几个方面进行优化。
设置本地 RocksDB 的数据目录
Checkpoint 参数相关配置
RocksDB 参数相关配置
12.2.6 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/IeAYbEy



