
第十章 —— Flink 最佳实践
本章将介绍两个最佳实践,第一个是如何合理的配置重启策略,笔者通过自己的亲身经历来讲述配置重启策略的重要性,接着介绍了 Flink 中的重启策略和恢复策略的发展实现过程;第二个是如何去管理 Flink 作业的配置。两个实践大家可以参考,不一定要照搬运用在自己的公司,同时也希望你可以思考下自己是否有啥最佳实践可以分享。
10.1 如何设置 Flink Job RestartStrategy(重启策略)?
从使用 Flink 到至今,遇到的 Flink 有很多,解决的问题更多(含帮助微信好友解决问题),所以对于 Flink 可能遇到的问题及解决办法都比较清楚,那么在这章就给大家讲解下几个 Flink 中比较常遇到的问题的解决办法。
10.1.1 常见错误导致 Flink 作业重启
不知道大家是否有遇到过这样的问题:整个 Job 一直在重启,并且还会伴随着一些错误(可以通过 UI 查看 Exceptions 日志),以下三张图片中的错误信息是笔者曾经生产环境遇到过的一些问题。
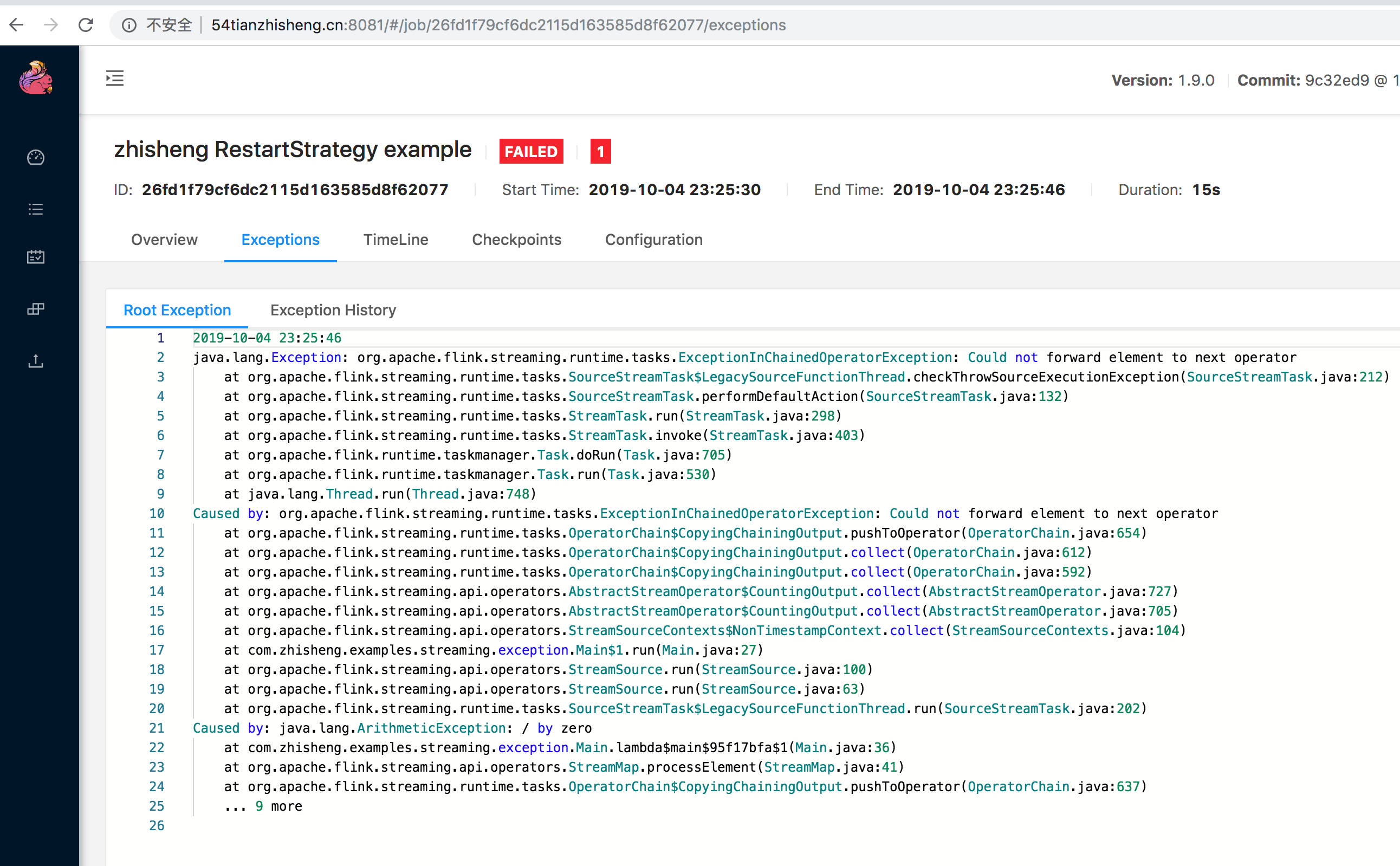
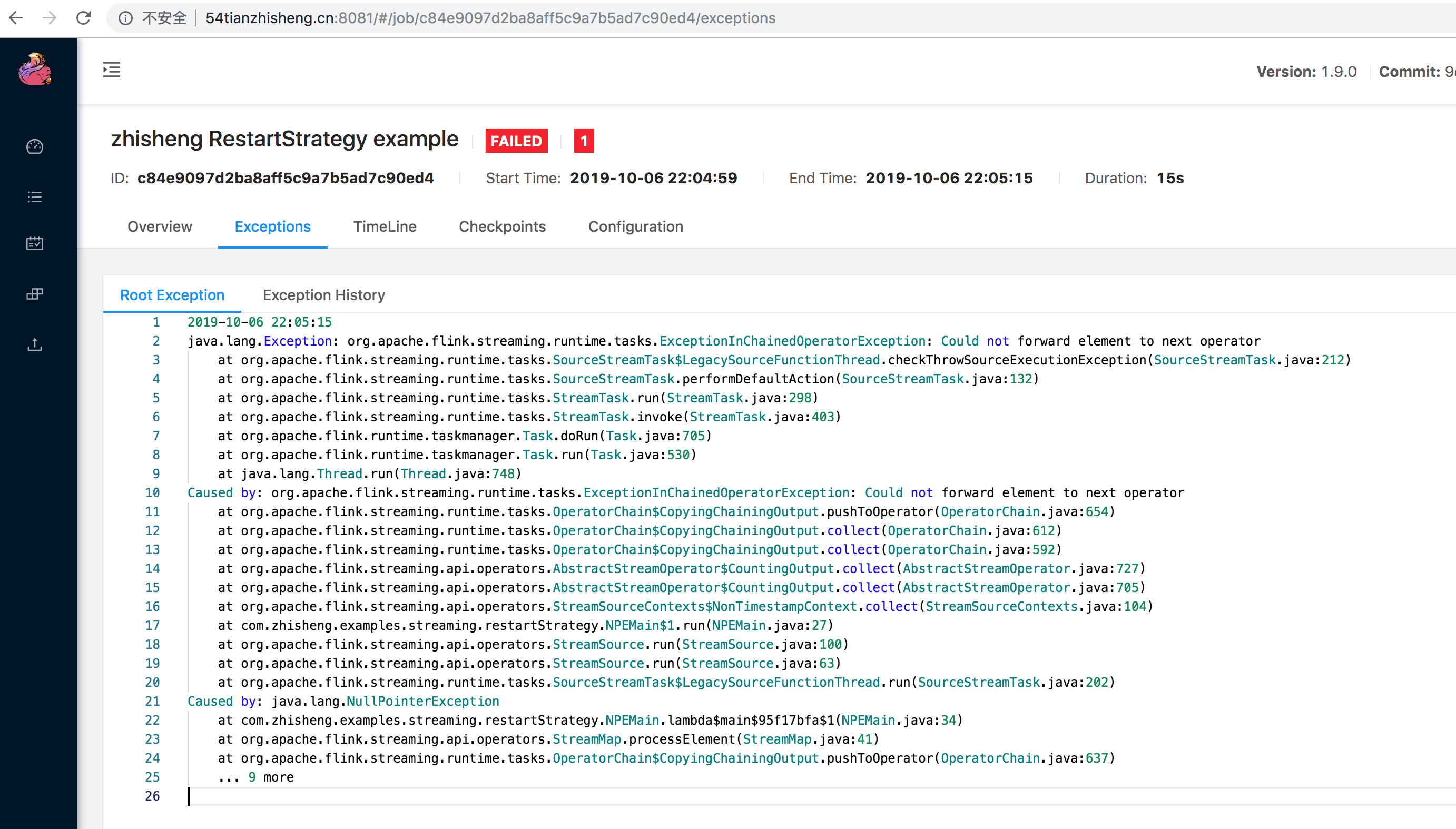
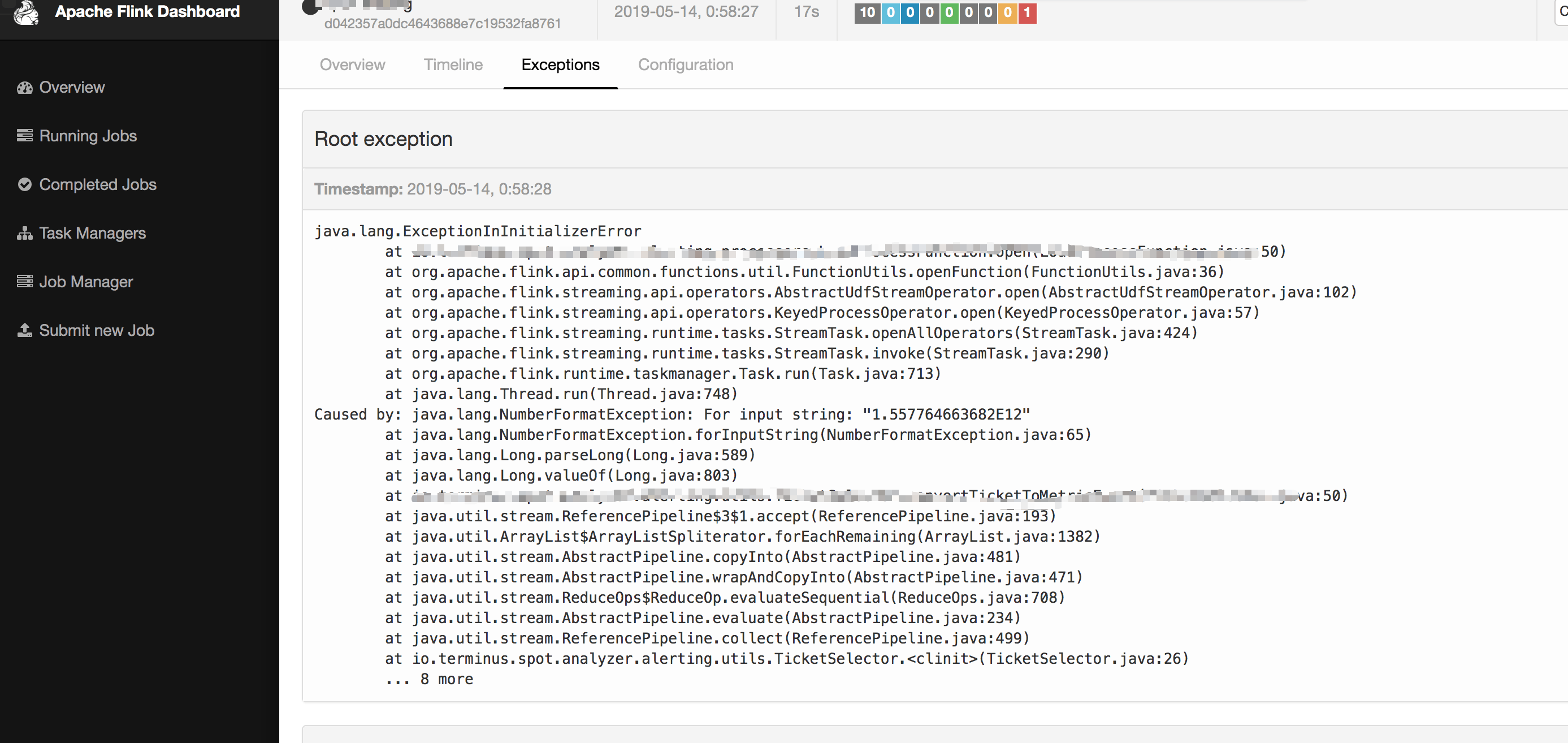
笔者就曾因为上图中的一个异常报错,作业一直重启,在深夜线上发版的时候,同事发现这个问题,凌晨两点的时候打电话把我叫醒起来修 BUG,真是惨的教训,哈哈哈,估计这辈子都忘不掉了!
其实遇到上面这种问题比较常见的,比如有时候因为数据的问题(不合规范、为 null 等),这时在处理这些脏数据的时候可能就会遇到各种各样的异常错误,比如空指针、数组越界、数据类型转换错误等。可能你会说只要过滤掉这种脏数据就行了,或者进行异常捕获就不会导致 Job 不断重启的问题了。
确实如此,如果做好了脏数据的过滤和异常的捕获,Job 的稳定性确实有保证,但是复杂的 Job 下每个算子可能都会产生出脏数据(包含源数据可能也会为空或者不合法的数据),你不可能在每个算子里面也用一个大的 try catch 做一个异常捕获,所以脏数据和异常简直就是防不胜防,不过我们还是要尽力的保证代码的健壮性,但是也要配置好 Flink Job 的 RestartStrategy(重启策略)。
10.1.2 RestartStrategy 简介
RestartStrategy,重启策略,在遇到机器或者代码等不可预知的问题时导致 Job 或者 Task 挂掉的时候,它会根据配置的重启策略将 Job 或者受影响的 Task 拉起来重新执行,以使得作业恢复到之前正常执行状态。Flink 中的重启策略决定了是否要重启 Job 或者 Task,以及重启的次数和每次重启的时间间隔。
10.1.3 为什么需要 RestartStrategy?
重启策略会让 Job 从上一次完整的 Checkpoint 处恢复状态,保证 Job 和挂之前的状态保持一致,另外还可以让 Job 继续处理数据,不会出现 Job 挂了导致消息出现大量堆积的问题,合理的设置重启策略可以减少 Job 不可用时间和避免人工介入处理故障的运维成本,因此重启策略对于 Flink Job 的稳定性来说有着举足轻重的作用。
10.1.4 如何配置 RestartStrategy?
既然 Flink 中的重启策略作用这么大,那么该如何配置呢?其实如果 Flink Job 没有单独设置重启重启策略的话,则会使用集群启动时加载的默认重启策略,如果 Flink Job 中单独设置了重启策略则会覆盖默认的集群重启策略。默认重启策略可以在 Flink 的配置文件 flink-conf.yaml 中设置,由 restart-strategy 参数控制,有 fixed-delay(固定延时重启策略)、failure-rate(故障率重启策略)、none(不重启策略)三种可以选择,如果选择的参数不同,对应的其他参数也不同。下面分别介绍这几种重启策略和如何配置。
FixedDelayRestartStrategy(固定延时重启策略)
FixedDelayRestartStrategy 是固定延迟重启策略,程序按照集群配置文件中或者程序中额外设置的重启次数尝试重启作业,如果尝试次数超过了给定的最大次数,程序还没有起来,则停止作业,另外还可以配置连续两次重启之间的等待时间,在 flink-conf.yaml 中可以像下面这样配置。
1 | restart-strategy: fixed-delay |
在程序中设置固定延迟重启策略的话如下:
1 | ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); |
FailureRateRestartStrategy(故障率重启策略)
FailureRateRestartStrategy 是故障率重启策略,在发生故障之后重启作业,如果固定时间间隔之内发生故障的次数超过设置的值后,作业就会失败停止,该重启策略也支持设置连续两次重启之间的等待时间。
1 | restart-strategy: failure-rate |
可以在应用程序中这样设置来配置故障率重启策略:
1 | ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); |
NoRestartStrategy(不重启策略)
NoRestartStrategy 作业不重启策略,直接失败停止,在 flink-conf.yaml 中配置如下:
1 | restart-strategy: none |
在程序中如下设置即可配置不重启:
1 | ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); |
Fallback(备用重启策略)
如果程序没有启用 Checkpoint,则采用不重启策略,如果开启了 Checkpoint 且没有设置重启策略,那么采用固定延时重启策略,最大重启次数为 Integer.MAX_VALUE。
在应用程序中配置好了固定延时重启策略,可以测试一下代码异常后导致 Job 失败后重启的情况,然后观察日志,可以看到 Job 重启相关的日志:
1 | [flink-akka.actor.default-dispatcher-5] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Try to restart or fail the job zhisheng default RestartStrategy example (a890361aed156610b354813894d02cd0) if no longer possible. |
最后重启次数达到配置的最大重启次数后 Job 还没有起来的话,则会停止 Job 并打印日志:
1 | [flink-akka.actor.default-dispatcher-2] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Could not restart the job zhisheng default RestartStrategy example (a890361aed156610b354813894d02cd0) because the restart strategy prevented it. |
Flink 中几种重启策略的设置如上,大家可以根据需要选择合适的重启策略,比如如果程序抛出了空指针异常,但是你配置的是一直无限重启,那么就会导致 Job 一直在重启,这样无非再浪费机器资源,这种情况下可以配置重试固定次数,每次隔多久重试的固定延时重启策略,这样在重试一定次数后 Job 就会停止,如果对 Job 的状态做了监控告警的话,那么你就会收到告警信息,这样也会提示你去查看 Job 的运行状况,能及时的去发现和修复 Job 的问题。
10.1.5 RestartStrategy 源码分析
再介绍重启策略应用程序代码配置的时候不知道你有没有看到设置重启策略都是使用 RestartStrategies 类,通过该类的方法就可以创建不同的重启策略,在 RestartStrategies 类中提供了五个方法用来创建四种不同的重启策略(有两个方法是创建 FixedDelay 重启策略的,只不过方法的参数不同),如下图所示。
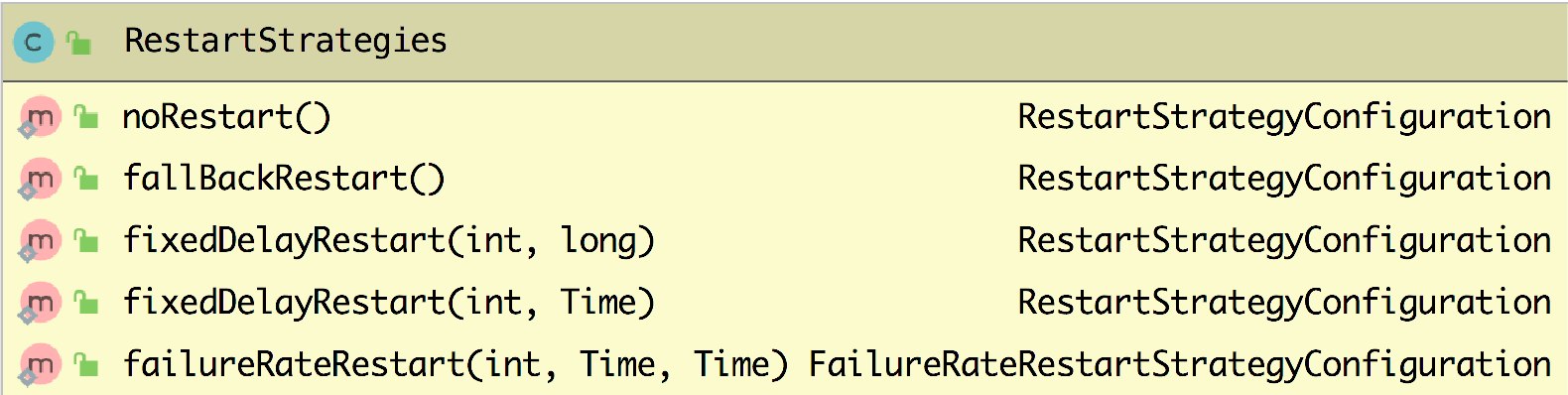
在每个方法内部其实调用的是 RestartStrategies 中的内部静态类,分别是 NoRestartStrategyConfiguration、FixedDelayRestartStrategyConfiguration、FailureRateRestartStrategyConfiguration、FallbackRestartStrategyConfiguration,这四个类都继承自 RestartStrategyConfiguration 抽象类,如下图所示。
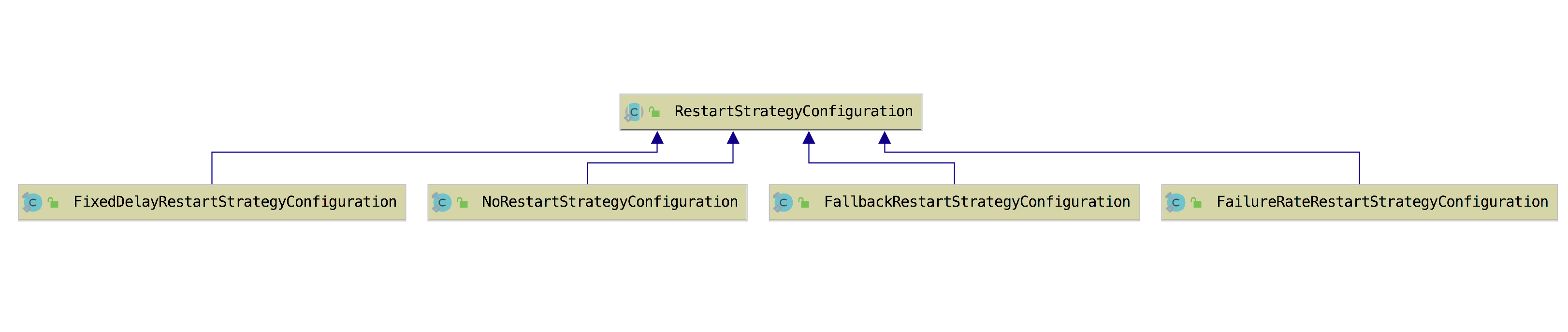
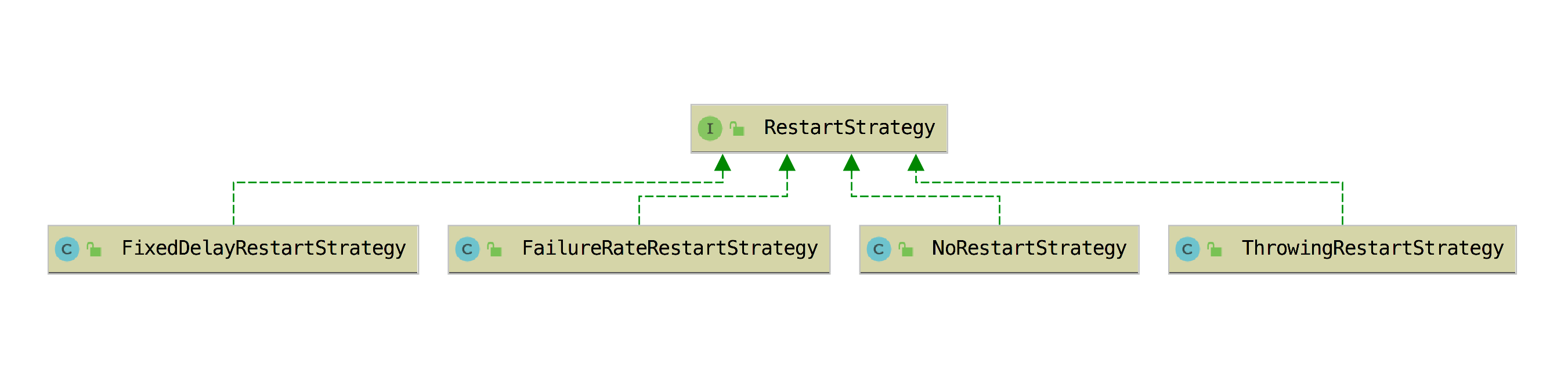
上面是定义的四种重启策略的配置类,在 Flink 中是靠 RestartStrategyResolving 类中的 resolve 方法来解析 RestartStrategies.RestartStrategyConfiguration,然后根据配置使用 RestartStrategyFactory 创建 RestartStrategy。RestartStrategy 是一个接口,它有 canRestart 和 restart 两个方法,它有四个实现类: FixedDelayRestartStrategy、FailureRateRestartStrategy、ThrowingRestartStrategy、NoRestartStrategy,如下图所示。
10.1.6 Failover Strategies(故障恢复策略)
重启所有的任务
基于 Region 的局部故障重启策略
10.1.7 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/RBYj66M



