
Apache Flink 自2017年12月发布的1.4.0版本开始,为流计算引入了一个重要的里程碑特性:TwoPhaseCommitSinkFunction(相关的 Jira)。它提取了两阶段提交协议的通用逻辑,使得通过 Flink 来构建端到端的 Exactly-Once 程序成为可能。同时支持一些数据源(source)和输出端(sink),包括 Apache Kafka 0.11及更高版本。它提供了一个抽象层,用户只需要实现少数方法就能实现端到端的 Exactly-Once 语义。
本文作者是 Piotr Nowojski,翻译自 周凯波
原文地址:https://www.ververica.com/blog/end-to-end-exactly-once-processing-apache-flink-apache-kafka
有关 TwoPhaseCommitSinkFunction 的使用详见文档: TwoPhaseCommitSinkFunction。或者可以直接阅读 Kafka 0.11 sink 的文档: kafka。
接下来会详细分析这个新功能以及Flink的实现逻辑,分为如下几点。
- 描述 Flink checkpoint 机制是如何保证Flink程序结果的 Exactly-Once 的
- 显示 Flink 如何通过两阶段提交协议与数据源和数据输出端交互,以提供端到端的 Exactly-Once 保证
- 通过一个简单的示例,了解如何使用 TwoPhaseCommitSinkFunction 实现 Exactly-Once 的文件输出
Flink 应用程序中的 Exactly-Once 语义
当我们说『Exactly-Once』时,指的是每个输入的事件只影响最终结果一次。即使机器或软件出现故障,既没有重复数据,也不会丢数据。
Flink 很久之前就提供了 Exactly-Once 语义。在过去几年中,我们对 Flink 的 checkpoint 机制有过深入的描述,这是 Flink 有能力提供 Exactly-Once 语义的核心。Flink 文档还提供了该功能的全面概述。
在继续之前,先看下对 checkpoint 机制的简要介绍,这对理解后面的主题至关重要。
一次 checkpoint 是以下内容的一致性快照:
- 应用程序的当前状态
- 输入流的位置
Flink 可以配置一个固定的时间点,定期产生 checkpoint,将 checkpoint 的数据写入持久存储系统,例如 S3 或 HDFS 。将 checkpoint 数据写入持久存储是异步发生的,这意味着 Flink 应用程序在 checkpoint 过程中可以继续处理数据。
如果发生机器或软件故障,重新启动后,Flink 应用程序将从最新的 checkpoint 点恢复处理; Flink 会恢复应用程序状态,将输入流回滚到上次 checkpoint 保存的位置,然后重新开始运行。这意味着 Flink 可以像从未发生过故障一样计算结果。
在 Flink 1.4.0 之前,Exactly-Once 语义仅限于 Flink 应用程序内部,并没有扩展到 Flink 数据处理完后发送的大多数外部系统。Flink 应用程序与各种数据输出端进行交互,开发人员需要有能力自己维护组件的上下文来保证 Exactly-Once 语义。
为了提供端到端的 Exactly-Once 语义 - 也就是说,除了 Flink 应用程序内部, Flink 写入的外部系统也需要能满足 Exactly-Once 语义 - 这些外部系统必须提供提交或回滚的方法,然后通过 Flink 的 checkpoint 机制来协调。
分布式系统中,协调提交和回滚的常用方法是两阶段提交协议。在下一节中,我们将讨论 Flink 的 TwoPhaseCommitSinkFunction 是如何利用两阶段提交协议来提供端到端的 Exactly-Once 语义。
Flink 应用程序端到端的 Exactly-Once 语义
我们将介绍两阶段提交协议,以及它如何在一个读写 Kafka 的 Flink 程序中实现端到端的 Exactly-Once 语义。Kafka 是一个流行的消息中间件,经常与 Flink 一起使用。Kafka 在最近的 0.11 版本中添加了对事务的支持。这意味着现在通过 Flink 读写 Kafka ,并提供端到端的 Exactly-Once 语义有了必要的支持。
Flink 对端到端的 Exactly-Once 语义的支持不仅局限于 Kafka ,您可以将它与任何一个提供了必要的协调机制的源/输出端一起使用。例如 Pravega,来自 DELL/EMC 的开源流媒体存储系统,通过 Flink 的 TwoPhaseCommitSinkFunction 也能支持端到端的 Exactly-Once 语义。
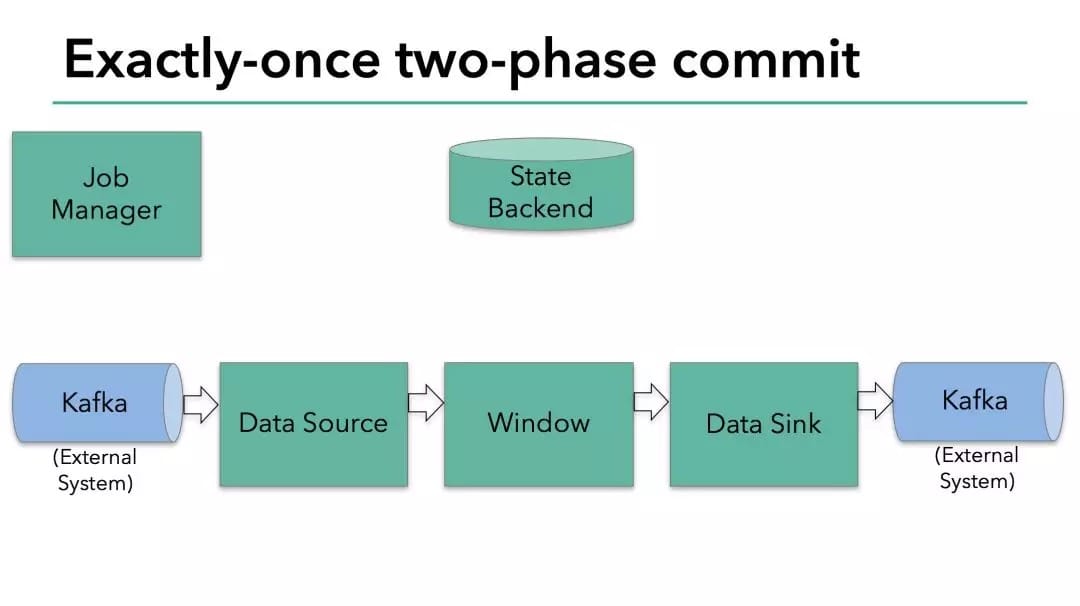
在今天讨论的这个示例程序中,我们有:
从 Kafka 读取的数据源( Flink 内置的 KafkaConsumer)
窗口聚合
将数据写回 Kafka 的数据输出端( Flink 内置的 KafkaProducer )
要使数据输出端提供 Exactly-Once 保证,它必须将所有数据通过一个事务提交给 Kafka。提交捆绑了两个 checkpoint 之间的所有要写入的数据。这可确保在发生故障时能回滚写入的数据。但是在分布式系统中,通常会有多个并发运行的写入任务的,简单的提交或回滚是不够的,因为所有组件必须在提交或回滚时“一致”才能确保一致的结果。Flink 使用两阶段提交协议及预提交阶段来解决这个问题。
在 checkpoint 开始的时候,即两阶段提交协议的“预提交”阶段。当 checkpoint 开始时,Flink 的 JobManager 会将 checkpoint barrier(将数据流中的记录分为进入当前 checkpoint 与进入下一个 checkpoint )注入数据流。
brarrier 在 operator 之间传递。对于每一个 operator,它触发 operator 的状态快照写入到 state backend。
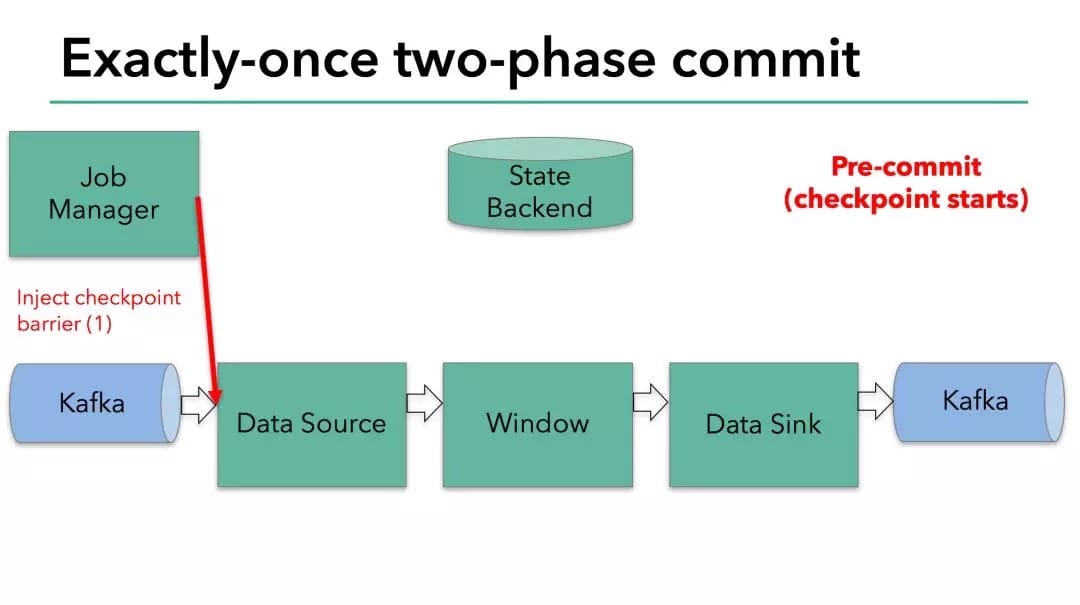
数据源保存了消费 Kafka 的偏移量(offset),之后将 checkpoint barrier 传递给下一个 operator。
这种方式仅适用于 operator 具有『内部』状态。所谓内部状态,是指 Flink statebackend 保存和管理的 -例如,第二个 operator 中 window 聚合算出来的 sum 值。当一个进程有它的内部状态的时候,除了在 checkpoint 之前需要将数据变更写入到 state backend ,不需要在预提交阶段执行任何其他操作。Flink 负责在 checkpoint 成功的情况下正确提交这些写入,或者在出现故障时中止这些写入。
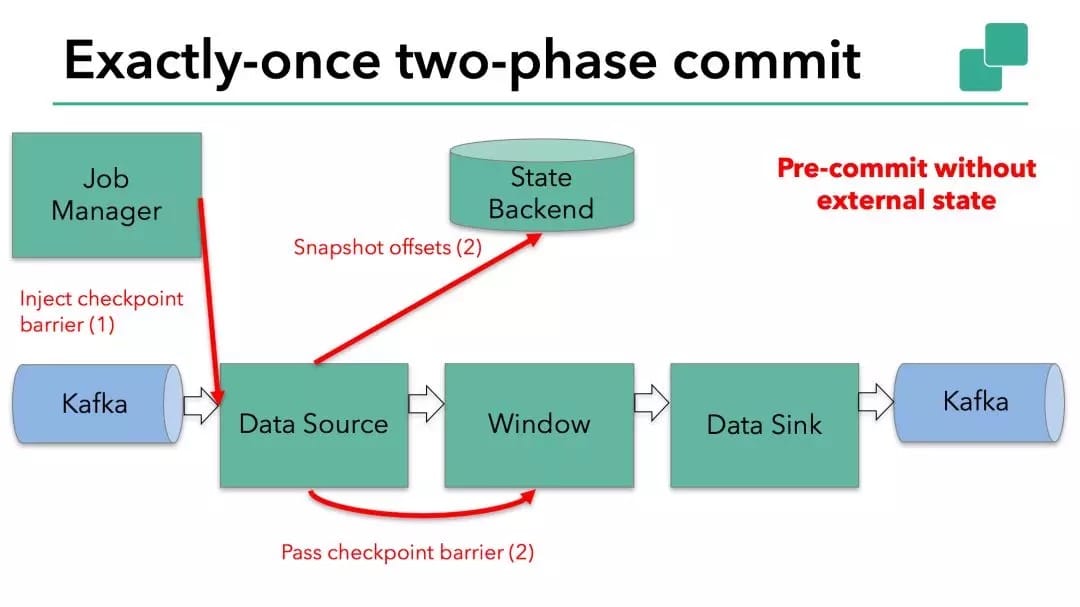
示例 Flink 应用程序启动预提交阶段
但是,当进程具有『外部』状态时,需要作些额外的处理。外部状态通常以写入外部系统(如 Kafka)的形式出现。在这种情况下,为了提供 Exactly-Once 保证,外部系统必须支持事务,这样才能和两阶段提交协议集成。
在本文示例中的数据需要写入 Kafka,因此数据输出端( Data Sink )有外部状态。在这种情况下,在预提交阶段,除了将其状态写入 state backend 之外,数据输出端还必须预先提交其外部事务。
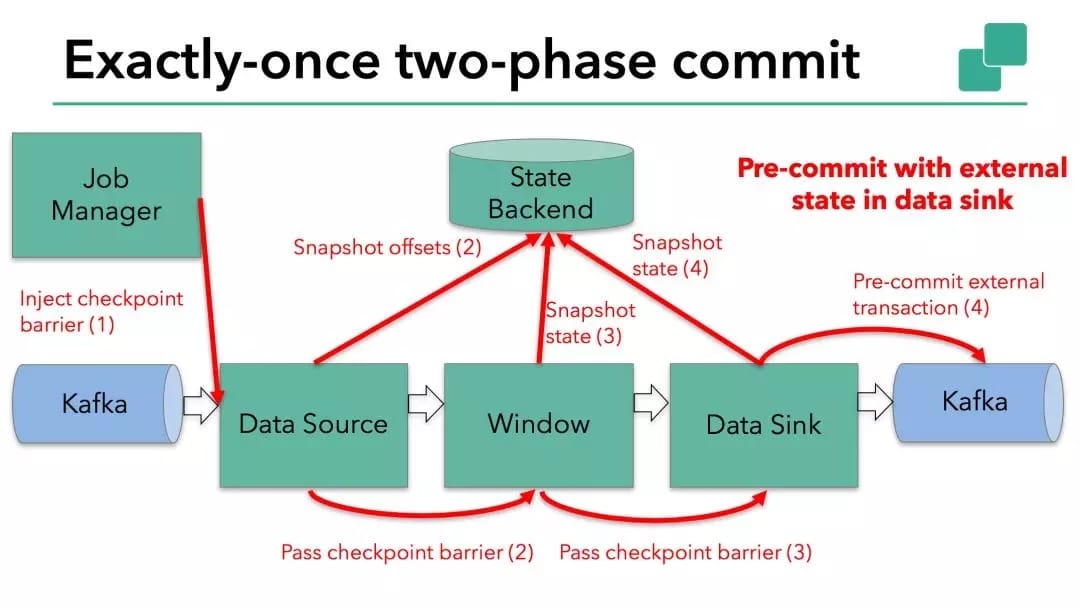
当 checkpoint barrier 在所有 operator 都传递了一遍,并且触发的 checkpoint 回调成功完成时,预提交阶段就结束了。所有触发的状态快照都被视为该 checkpoint 的一部分。checkpoint 是整个应用程序状态的快照,包括预先提交的外部状态。如果发生故障,我们可以回滚到上次成功完成快照的时间点。
下一步是通知所有 operator,checkpoint 已经成功了。这是两阶段提交协议的提交阶段,JobManager 为应用程序中的每个 operator 发出 checkpoint 已完成的回调。
数据源和 windnow operator 没有外部状态,因此在提交阶段,这些 operator 不必执行任何操作。但是,数据输出端(Data Sink)拥有外部状态,此时应该提交外部事务。
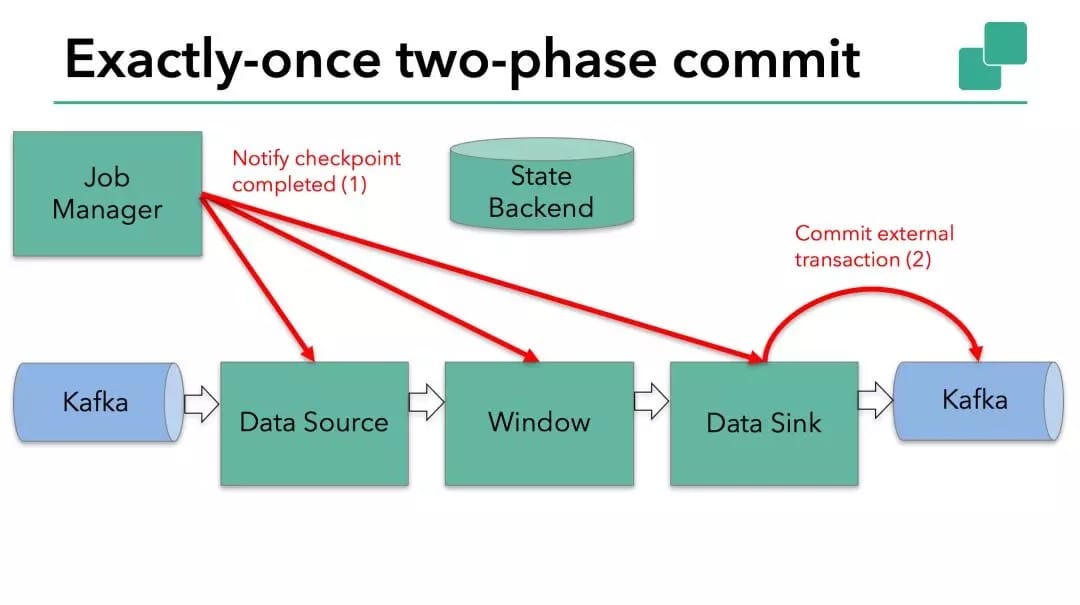
我们对上述知识点总结下:
一旦所有 operator 完成预提交,就提交一个 commit。
如果至少有一个预提交失败,则所有其他提交都将中止,我们将回滚到上一个成功完成的 checkpoint 。
在预提交成功之后,提交的 commit 需要保证最终成功 - operator 和外部系统都需要保障这点。如果 commit 失败(例如,由于间歇性网络问题),整个 Flink 应用程序将失败,应用程序将根据用户的重启策略重新启动,还会尝试再提交。这个过程至关重要,因为如果 commit 最终没有成功,将会导致数据丢失。
因此,我们可以确定所有 operator 都同意 checkpoint 的最终结果:所有 operator 都同意数据已提交,或提交被中止并回滚。
在 Flink 中实现两阶段提交 Operator
完整的实现两阶段提交协议可能有点复杂,这就是为什么 Flink 将它的通用逻辑提取到抽象类 TwoPhaseCommitSinkFunction 中的原因。
接下来基于输出到文件的简单示例,说明如何使用 TwoPhaseCommitSinkFunction 。用户只需要实现四个函数,就能为数据输出端实现 Exactly-Once 语义:
beginTransaction - 在事务开始前,我们在目标文件系统的临时目录中创建一个临时文件。随后,我们可以在处理数据时将数据写入此文件。
preCommit - 在预提交阶段,我们刷新文件到存储,关闭文件,不再重新写入。我们还将为属于下一个 checkpoint 的任何后续文件写入启动一个新的事务。
commit - 在提交阶段,我们将预提交阶段的文件原子地移动到真正的目标目录。需要注意的是,这会增加输出数据可见性的延迟。
abort - 在中止阶段,我们删除临时文件。
我们知道,如果发生任何故障,Flink 会将应用程序的状态恢复到最新的一次 checkpoint 点。一种极端的情况是,预提交成功了,但在这次 commit 的通知到达 operator 之前发生了故障。在这种情况下,Flink 会将 operator 的状态恢复到已经预提交,但尚未真正提交的状态。
我们需要在预提交阶段保存足够多的信息到 checkpoint 状态中,以便在重启后能正确的中止或提交事务。在这个例子中,这些信息是临时文件和目标目录的路径。
TwoPhaseCommitSinkFunction 已经把这种情况考虑在内了,并且在从 checkpoint 点恢复状态时,会优先发出一个 commit 。我们需要以幂等方式实现提交,一般来说,这并不难。在这个示例中,我们可以识别出这样的情况:临时文件不在临时目录中,但已经移动到目标目录了。
在 TwoPhaseCommitSinkFunction 中,还有一些其他边界情况也会考虑在内,请参考 Flink 文档了解更多信息。
总结
总结下本文涉及的一些要点:
Flink 的 checkpoint 机制是支持两阶段提交协议并提供端到端的 Exactly-Once 语义的基础。
这个方案的优点是: Flink 不像其他一些系统那样,通过网络传输存储数据 - 不需要像大多数批处理程序那样将计算的每个阶段写入磁盘。
Flink 的 TwoPhaseCommitSinkFunction 提取了两阶段提交协议的通用逻辑,基于此将 Flink 和支持事务的外部系统结合,构建端到端的 Exactly-Once 成为可能。
从 Flink 1.4.0 开始,Pravega 和 Kafka 0.11 producer 都提供了 Exactly-Once 语义;Kafka 在0.11版本首次引入了事务,为在 Flink 程序中使用 Kafka producer 提供 Exactly-Once 语义提供了可能性。
Kafka 0.11 producer的事务是在 TwoPhaseCommitSinkFunction 基础上实现的,和 at-least-once producer 相比只增加了非常低的开销。
这是个令人兴奋的功能,期待 Flink TwoPhaseCommitSinkFunction 在未来支持更多的数据接收端。
最后
GitHub Flink 学习代码地址:https://github.com/zhisheng17/flink-learning
微信公众号:zhisheng
另外我自己整理了些 Flink 的学习资料,目前已经全部放到微信公众号(zhisheng)了,你可以回复关键字:Flink 即可无条件获取到。另外也可以加我微信 你可以加我的微信:yuanblog_tzs,探讨技术!

更多私密资料请加入知识星球!

专栏介绍
首发地址:http://www.54tianzhisheng.cn/2019/11/15/flink-in-action/
专栏地址:https://gitbook.cn/gitchat/column/5dad4a20669f843a1a37cb4f
博客
1、Flink 从0到1学习 —— Apache Flink 介绍
2、Flink 从0到1学习 —— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
3、Flink 从0到1学习 —— Flink 配置文件详解
4、Flink 从0到1学习 —— Data Source 介绍
5、Flink 从0到1学习 —— 如何自定义 Data Source ?
6、Flink 从0到1学习 —— Data Sink 介绍
7、Flink 从0到1学习 —— 如何自定义 Data Sink ?
8、Flink 从0到1学习 —— Flink Data transformation(转换)
9、Flink 从0到1学习 —— 介绍 Flink 中的 Stream Windows
10、Flink 从0到1学习 —— Flink 中的几种 Time 详解
11、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 ElasticSearch
12、Flink 从0到1学习 —— Flink 项目如何运行?
13、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Kafka
14、Flink 从0到1学习 —— Flink JobManager 高可用性配置
15、Flink 从0到1学习 —— Flink parallelism 和 Slot 介绍
16、Flink 从0到1学习 —— Flink 读取 Kafka 数据批量写入到 MySQL
17、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RabbitMQ
18、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HBase
19、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HDFS
20、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Redis
21、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Cassandra
22、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Flume
23、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 InfluxDB
24、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RocketMQ
25、Flink 从0到1学习 —— 你上传的 jar 包藏到哪里去了
26、Flink 从0到1学习 —— 你的 Flink job 日志跑到哪里去了
28、Flink 从0到1学习 —— Flink 中如何管理配置?
29、Flink 从0到1学习—— Flink 不可以连续 Split(分流)?
30、Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
32、为什么说流处理即未来?
33、OPPO 数据中台之基石:基于 Flink SQL 构建实时数据仓库
36、Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
38、如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
40、Flink 全网最全资源(视频、博客、PPT、入门、原理、实战、性能调优、源码解析、问答等持续更新)
42、Flink 从0到1学习 —— 如何使用 Side Output 来分流?
源码解析
4、Flink 源码解析 —— standalone session 模式启动流程
5、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Job Manager 启动
6、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Task Manager 启动
7、Flink 源码解析 —— 分析 Batch WordCount 程序的执行过程
8、Flink 源码解析 —— 分析 Streaming WordCount 程序的执行过程
9、Flink 源码解析 —— 如何获取 JobGraph?
10、Flink 源码解析 —— 如何获取 StreamGraph?
11、Flink 源码解析 —— Flink JobManager 有什么作用?
12、Flink 源码解析 —— Flink TaskManager 有什么作用?
13、Flink 源码解析 —— JobManager 处理 SubmitJob 的过程
14、Flink 源码解析 —— TaskManager 处理 SubmitJob 的过程
15、Flink 源码解析 —— 深度解析 Flink Checkpoint 机制
16、Flink 源码解析 —— 深度解析 Flink 序列化机制
17、Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
18、Flink Metrics 源码解析 —— Flink-metrics-core
19、Flink Metrics 源码解析 —— Flink-metrics-datadog
20、Flink Metrics 源码解析 —— Flink-metrics-dropwizard
21、Flink Metrics 源码解析 —— Flink-metrics-graphite
22、Flink Metrics 源码解析 —— Flink-metrics-influxdb
23、Flink Metrics 源码解析 —— Flink-metrics-jmx
24、Flink Metrics 源码解析 —— Flink-metrics-slf4j
25、Flink Metrics 源码解析 —— Flink-metrics-statsd
26、Flink Metrics 源码解析 —— Flink-metrics-prometheus

27、Flink 源码解析 —— 如何获取 ExecutionGraph ?


