9.2 如何查看 Flink 作业执行计划? 当一个应用程序需求比较简单的情况下,数据转换涉及的 operator(算子)可能不多,但是当应用的需求变得越来越复杂时,可能在一个 Job 里面算子的个数会达到几十个、甚至上百个,在如此多算子的情况下,整个应用程序就会变得非常复杂,所以在编写 Flink Job 的时候要是能够随时知道 Job 的执行计划那就很方便了。
刚好,Flink 是支持可以获取到整个 Job 的执行计划的,另外 Flink 官网还提供了一个可视化工具 visualizer(可以将执行计划 JSON 绘制出执行图),如下图所示。
9.2.1 如何获取执行计划 JSON? 既然知道了将执行计划 JSON 绘制出可查看的执行图的工具,那么该如何获取执行计划 JSON 呢?方法很简单,你只需要在你的 Flink Job 的 Main 方法 里面加上这么一行代码:
1 System.out.println(env.getExecutionPlan());
然后就可以在 IDEA 中右键 Run 一下你的 Flink Job,从打印的日志里面可以查看到执行计划的 JSON 串,例如下面这种:
1 {"nodes" :[{"id" :1 ,"type" :"Source: Custom Source" ,"pact" :"Data Source" ,"contents" :"Source: Custom Source" ,"parallelism" :5 },{"id" :2 ,"type" :"Sink: flink-connectors-kafka" ,"pact" :"Data Sink" ,"contents" :"Sink: flink-connectors-kafka" ,"parallelism" :5 ,"predecessors" :[{"id" :1 ,"ship_strategy" :"FORWARD" ,"side" :"second" }]}]}
IDEA 中运行打印出来的执行计划的 JSON 串如下图所示:
9.2.2 生成执行计划图 获取到执行计划 JSON 了,那么利用 Flink 自带的工具来绘出执行计划图,将获得到的 JSON 串复制粘贴到刚才那网址去,如下图所示。
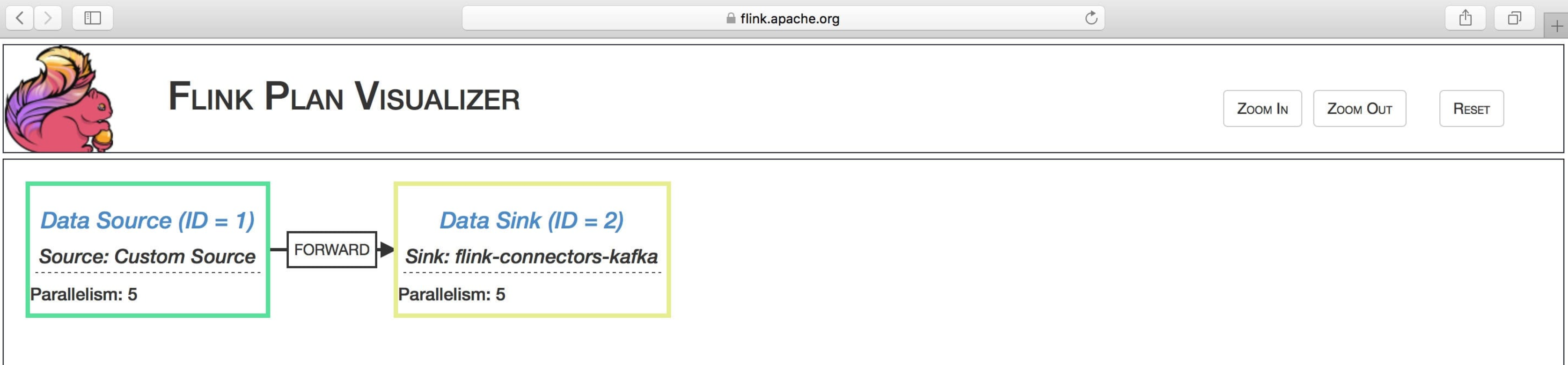
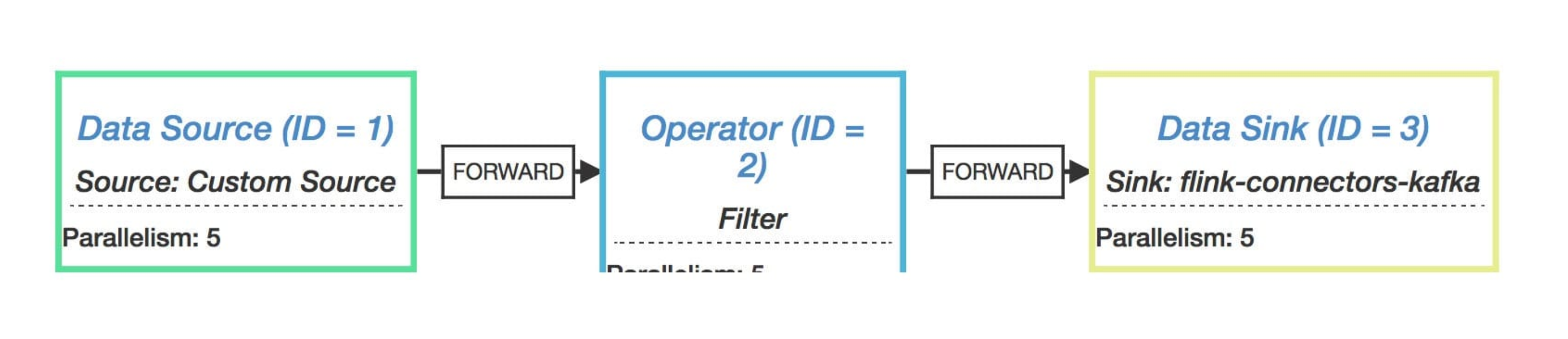
点击上图的 Draw 按钮,就会生成如下图所示的执行流程图了。
从图中我们可以看到哪些内容呢?
operator name(算子):比如 source、sink
每个 operator 的并行度:比如 Parallelism: 5
数据下发的类型:比如 FORWARD
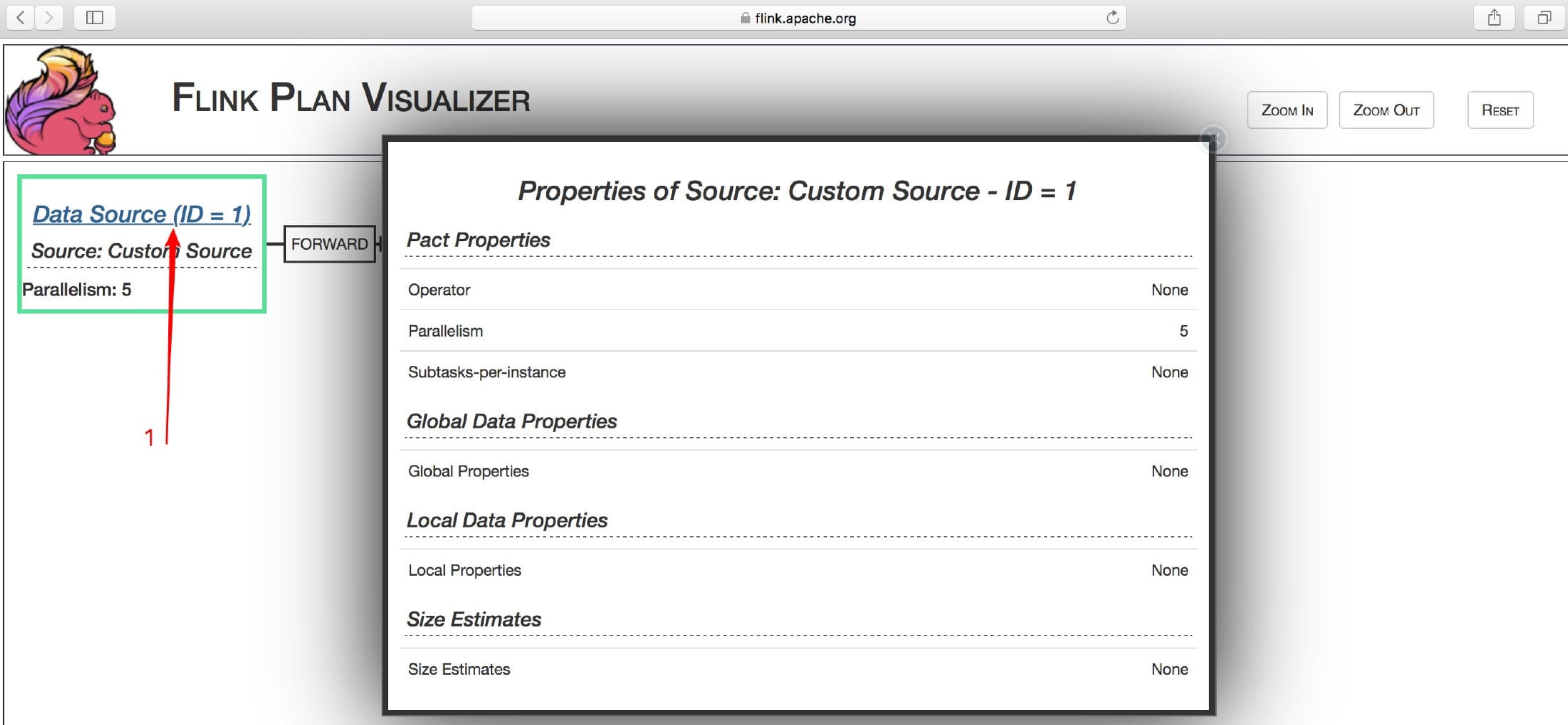
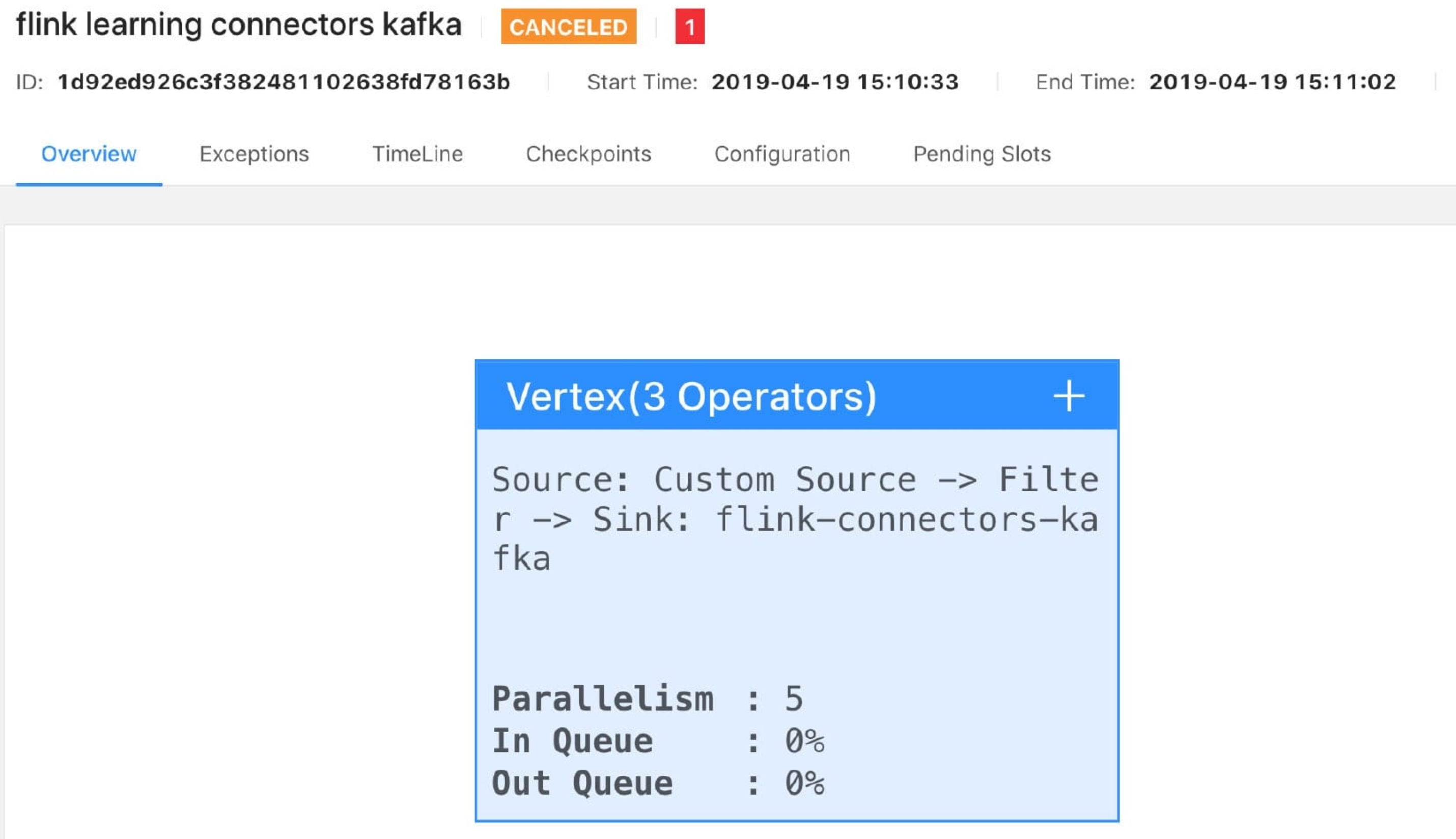
你还可以点击下图中的 Data Source(ID = 1) 查看具体详情,如下图所示:
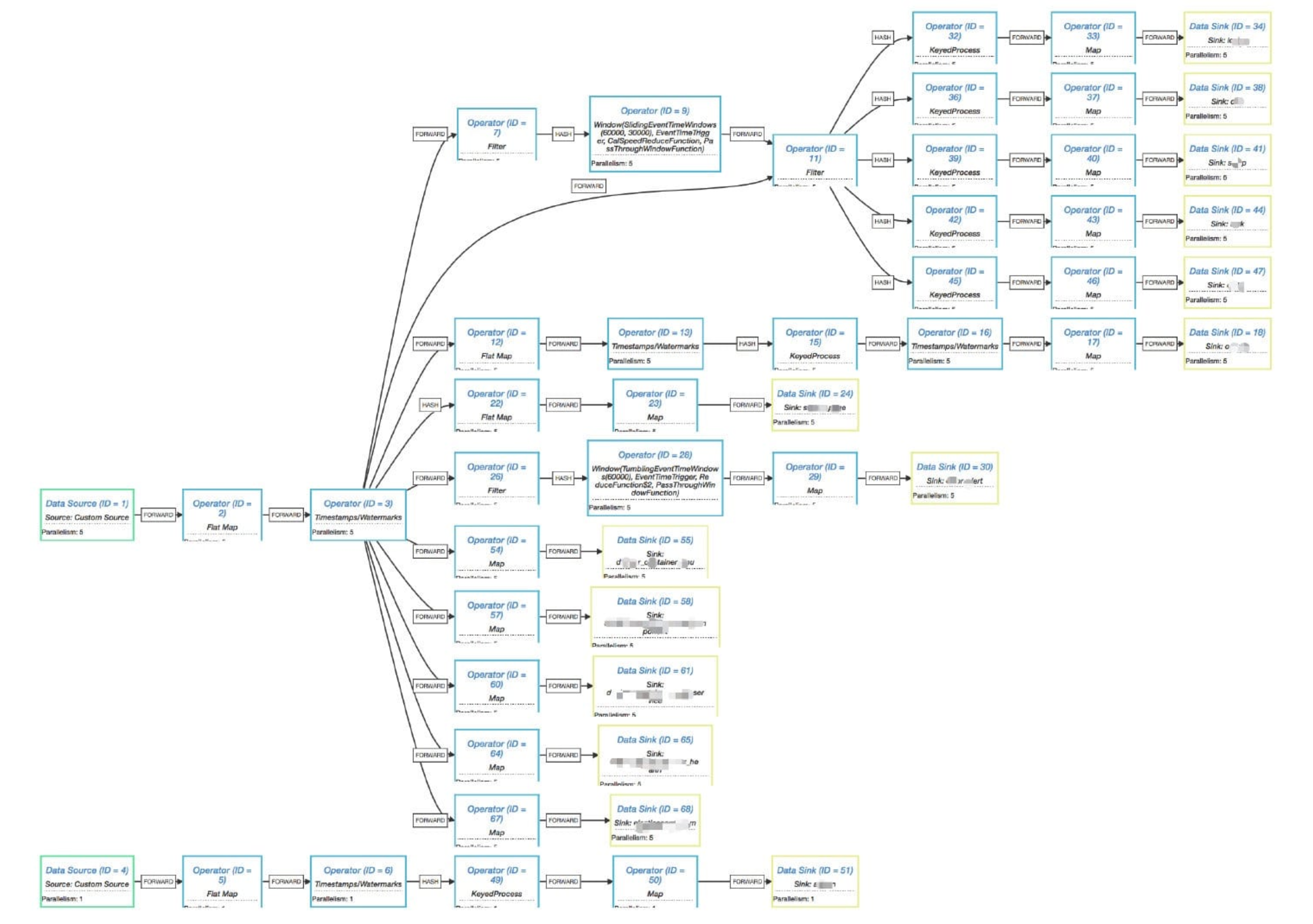
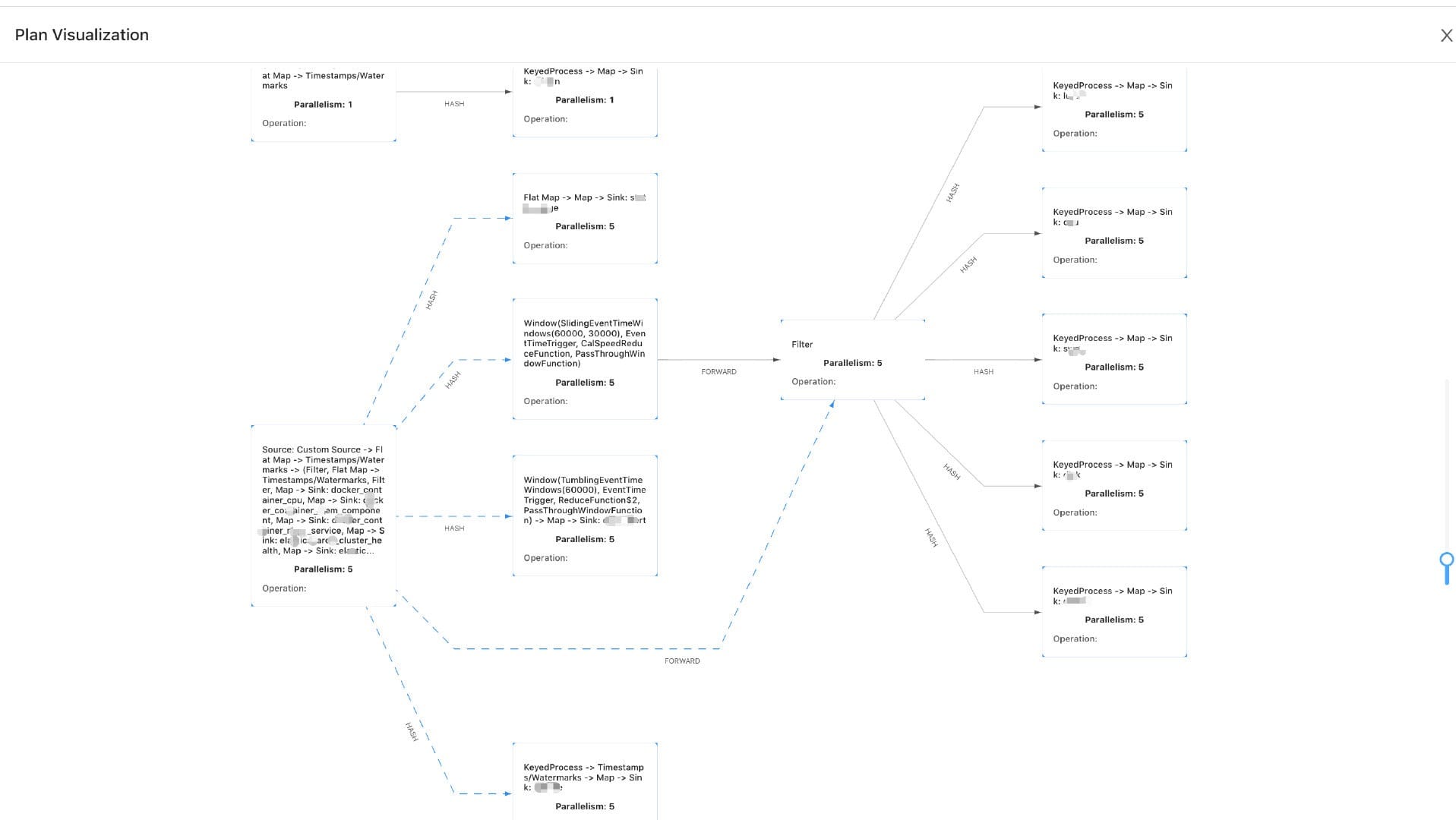
随着需求的不段增加,可能算子的个数会增加,所以执行计划也会变得更为复杂,如下图所示。
看到上图是不是觉得就有点很复杂了,笔者相信可能你自己的业务需求比这还会复杂得更多,不过从这图我们可以看到比上面那个简单的执行计划图多了一种数据下发类型就是 HASH。但是大家可能会好奇的说:为什么我平时从 Flink UI 上查看到的 Job ”执行计划图“ 却不是这样子的呀?
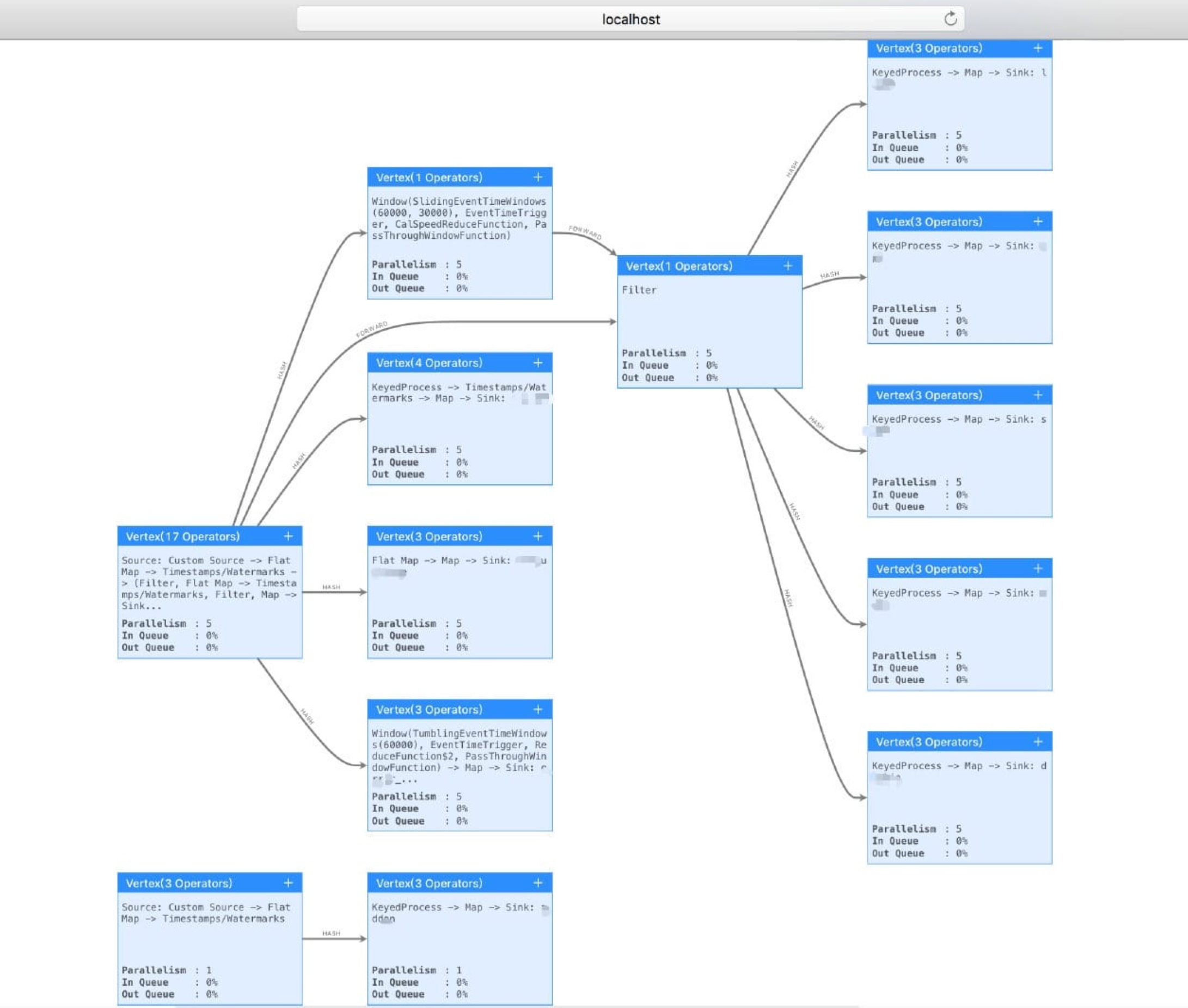
这里我们复现一下这个问题,我们把这个稍微复杂的 Flink Job 提交到 Flink UI 上去查看一下到底它在 UI 上的执行计划图是个什么样子?我们提交 Jar 包后不运行,直接点击 show plan 的结果如下图所示。
我们再运行一下,查看运行的时候的展示的 “执行计划图” 又是不一样的,如下图所示。
9.2.3 深入探究 Flink 作业执行计划 我们可以发现这两个 “执行计划图” 都和在 Flink 官网提供的 visualizer 工具生成的执行计划图是不一样的。粗略观察可以发现:在 Flink UI 上面的 “执行计划图” 变得更加简洁了,有些算子合在一起了,所以整体看起来就没这么复杂了。其实,这是 Flink 内部做的一个优化。我们先来看下 env.getExecutionPlan() 这段代码它背后的逻辑:
1 2 3 4 5 6 7 8 9 10 11 public String getExecutionPlan () return getStreamGraph().getStreamingPlanAsJSON(); }
代码注释的大概意思是:
创建程序执行计划,并将执行数据流图的 JSON 作为 String 返回,请注意,在执行计划之前需要调用此方法。
这个 getExecutionPlan 方法有两步操作:
1、获取到 Job 的 StreamGraph
关于如何获取到 StreamGraph,笔者在博客里面写了篇源码解析 如何获取 StreamGraph? 。
2、将 StreamGraph 转换成 JSON
1 2 3 4 5 6 7 8 public String getStreamingPlanAsJSON () try { return new JSONGenerator(this ).getJSON(); } catch (Exception e) { throw new RuntimeException("JSON plan creation failed" , e); } }
跟进 getStreamingPlanAsJSON 方法看见它构造了一个 JSONGenerator 对象(含参 StreamGraph),然后调用 getJSON 方法,我们来看下这个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public String getJSON () ObjectNode json = mapper.createObjectNode(); ArrayNode nodes = mapper.createArrayNode(); json.put("nodes" , nodes); List<Integer> operatorIDs = new ArrayList<Integer>(streamGraph.getVertexIDs()); Collections.sort(operatorIDs, new Comparator<Integer>() { @Override public int compare (Integer idOne, Integer idTwo) boolean isIdOneSinkId = streamGraph.getSinkIDs().contains(idOne); boolean isIdTwoSinkId = streamGraph.getSinkIDs().contains(idTwo); ... } }); visit(nodes, operatorIDs, new HashMap<Integer, Integer>()); return json.toString(); }
一开始构造外部的对象,然后调用 visit 方法继续构造内部的对象,visit 方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 private void visit (ArrayNode jsonArray, List<Integer> toVisit, Map<Integer, Integer> edgeRemapings) Integer vertexID = toVisit.get(0 ); StreamNode vertex = streamGraph.getStreamNode(vertexID); if (streamGraph.getSourceIDs().contains(vertexID) || Collections.disjoint(vertex.getInEdges(), toVisit)) { ObjectNode node = mapper.createObjectNode(); decorateNode(vertexID, node); if (!streamGraph.getSourceIDs().contains(vertexID)) { ArrayNode inputs = mapper.createArrayNode(); node.put(PREDECESSORS, inputs); for (StreamEdge inEdge : vertex.getInEdges()) { int inputID = inEdge.getSourceId(); Integer mappedID = (edgeRemapings.keySet().contains(inputID)) ? edgeRemapings .get(inputID) : inputID; decorateEdge(inputs, inEdge, mappedID); } } jsonArray.add(node); toVisit.remove(vertexID); } else { Integer iterationHead = -1 ; for (StreamEdge inEdge : vertex.getInEdges()) { int operator = inEdge.getSourceId(); if (streamGraph.vertexIDtoLoopTimeout.containsKey(operator)) { iterationHead = operator; } } ObjectNode obj = mapper.createObjectNode(); ArrayNode iterationSteps = mapper.createArrayNode(); obj.put(STEPS, iterationSteps); obj.put(ID, iterationHead); obj.put(PACT, "IterativeDataStream" ); obj.put(PARALLELISM, streamGraph.getStreamNode(iterationHead).getParallelism()); obj.put(CONTENTS, "Stream Iteration" ); ArrayNode iterationInputs = mapper.createArrayNode(); obj.put(PREDECESSORS, iterationInputs); toVisit.remove(iterationHead); visitIteration(iterationSteps, toVisit, iterationHead, edgeRemapings, iterationInputs); jsonArray.add(obj); } if (!toVisit.isEmpty()) { visit(jsonArray, toVisit, edgeRemapings); } }
最后就将这个 StreamGraph 构造成一个 JSON 串返回出去,所以其实这里返回的执行计划图就是 Flink Job 的 StreamGraph,然而我们在 Flink UI 上面看到的 “执行计划图” 是对应 Flink 中的 JobGraph,同样,笔者在博客里面也写了篇源码解析的文章 源码解析——如何获取 JobGraph? 。
9.2.4 Flink 中算子链接(chain)起来的条件 Flink 在内部会将多个算子串在一起作为一个 operator chain(执行链)来执行,每个执行链会在 TaskManager 上的一个独立线程中执行,这样不仅可以减少线程的数量及线程切换带来的资源消耗,还能降低数据在算子之间传输序列化与反序列化带来的消耗。
举个例子,拿一个 Flink Job (算子的并行度都设置为 5)生成的 StreamGraph JSON 渲染出来的执行流程图如下图所示。
提交到 Flink UI 上的 JobGraph 如下图所示。
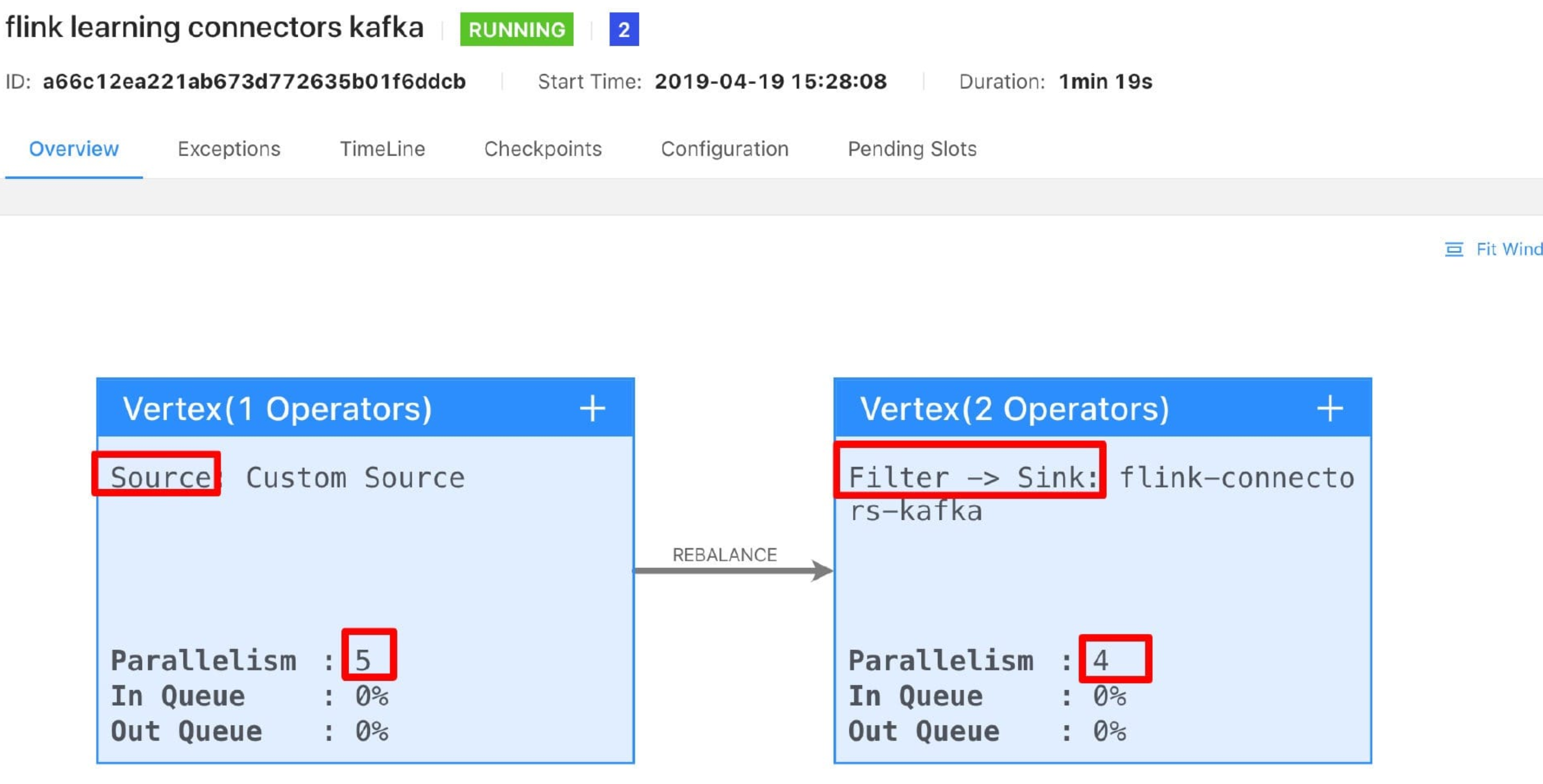
可以看到 Flink 它内部将三个算子(source、filter、sink)都串成在一个执行链里。但是我们修改一下 filter 这个算子的并行度为 4,我们再次提交到 Flink UI 上运行,效果如下图所示。
你会发现它竟然拆分成三个了,我们继续将 sink 的并行度也修改成 4,继续打包运行后的效果如下图所示。
神奇不,它变成了 2 个了,将 filter 和 sink 算子串在一起了执行了。经过简单的测试,我们可以发现其实如果想要把两个不一样的算子串在一起执行确实还不是那么简单的,的确,它背后的条件可是比较复杂的,这里笔者给出源码出来,感兴趣的可以独自阅读下源码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static boolean isChainable (StreamEdge edge, StreamGraph streamGraph) StreamNode upStreamVertex = edge.getSourceVertex(); StreamNode downStreamVertex = edge.getTargetVertex(); StreamOperator<?> headOperator = upStreamVertex.getOperator(); StreamOperator<?> outOperator = downStreamVertex.getOperator(); return downStreamVertex.getInEdges().size() == 1 && outOperator != null && headOperator != null && upStreamVertex.isSameSlotSharingGroup(downStreamVertex) && outOperator.getChainingStrategy() == ChainingStrategy.ALWAYS && (headOperator.getChainingStrategy() == ChainingStrategy.HEAD || headOperator.getChainingStrategy() == ChainingStrategy.ALWAYS) && (edge.getPartitioner() instanceof ForwardPartitioner) && upStreamVertex.getParallelism() == downStreamVertex.getParallelism() && streamGraph.isChainingEnabled(); }
从源码最后的 return 可以看出它有九个条件:
…
所以看到上面的这九个条件,你是不是在想如果我们代码能够合理的写好,那么就有可能会将不同的算子串在一个执行链中,这样也就可以提高代码的执行效率了。
9.2.5 如何禁止 Operator chain? 加入知识星球可以看到上面文章:https://t.zsxq.com/uFEEYzJ
9.2.6 小结与反思 本节内容从查看作业的执行计划来分析作业的执行情况,接着分析了作业算子 chain 起来的条件,并通过程序演示来验证,最后讲解了如何禁止算子 chain 起来。
本节代码地址:chain
Job visualizer 工具
源码解析——如何获取 StreamGraph