
第一章 —— 实时计算引擎
本章会从公司常见的计算需求去分析该如何实现这些需求,接着会对比分析实时计算与离线计算之间的区别,从而帮大家分析公司是否需要引入实时计算引擎。接着将会详细的介绍目前最火的实时计算引擎 Flink 的特性,让大家知道其优点,最后会对比其他的计算框架,比如 Spark、Storm 等,希望可以从对比结果来分析这几种计算框架的各自优势,从而为你做技术选型提供一点帮助。
1.1 你的公司是否需要引入实时计算引擎
大数据发展至今,数据呈指数倍的增长,对实效性的要求也越来越高,所以你可能接触到的实时计算需求会越来越多。本章节将从实时计算需求开始讲起,然后阐述完成该需求需要做的工作,最后对比实时计算与离线计算。
1.1.1 实时计算需求
在公司里面,你可能会收到领导、产品经理或者运营等提出的如下需求:
1 | 小田,你看能不能做个监控大屏实时查看促销活动商品总销售额(GMV)? |
那上面这些需求分别对应着什么业务场景呢?我们来总结下,大概如下图所示:
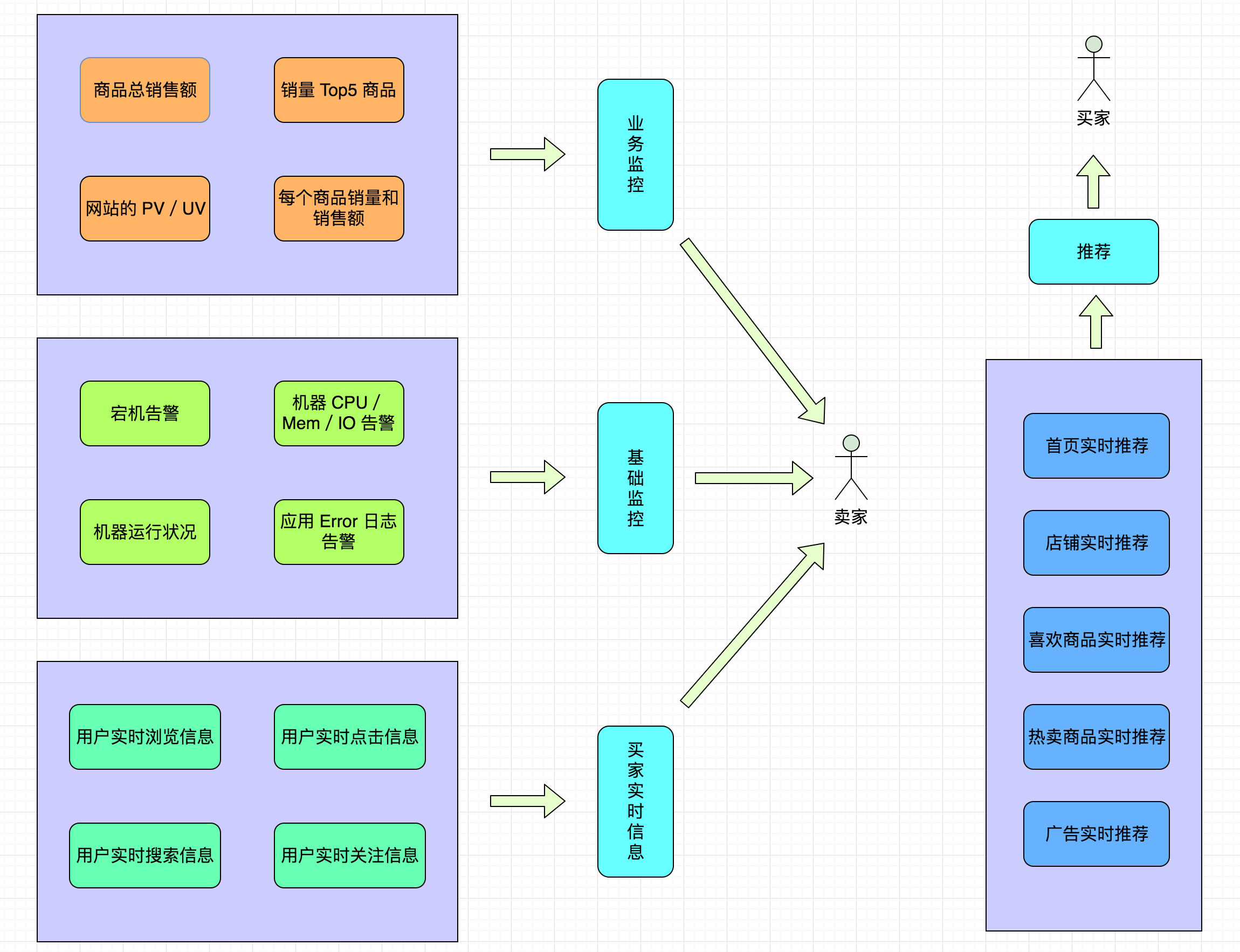
初看这些需求,你是不是感觉实现会比较难?那么接下来我们来分析一下该如何实现这些需求?从这些需求来看,最根本的业务都是需要实时查看数据信息,那么首先我们得想想如何实时去采集数据,然后将采集到的数据进行实时的计算,最后将计算后的结果下发到第三方。从采集到计算再到下发计算结果的整个过程,必须都得是实时的,这样我们看到的数据才是最接近实时的,这样才能够很完美的完成上面的这些实时计算需求。
1.1.2 数据实时采集
就上面这些需求,我们知道了需要实时去采集数据,但是针对这些需求,我们到底需要采集些什么数据呢?如下就是我们需要采集的数据:
- 用户搜索信息
- 用户浏览商品信息
- 用户下单订单信息
- 网站的所有浏览记录
- 机器 CPU/Mem/IO 信息
- 应用日志信息
1.1.3 数据实时计算
采集后的数据实时上报后,需要做实时的计算,那我们怎么实现计算呢?
- 计算所有商品的总销售额
- 统计单个商品的销量,最后求 Top5
- 关联用户信息和浏览信息、下单信息
- 统计网站所有的请求 IP 并统计每个 IP 的请求数量
- 计算一分钟内机器 CPU/Mem/IO 的平均值、75 分位数值
- 过滤出 Error 级别的日志信息
1.1.4 数据实时下发
实时计算后的数据,需要及时的下发到下游,这里说的下游代表可能是告警方式(邮件、短信、钉钉、微信)、存储(消息队列、DB、文件系统等)。
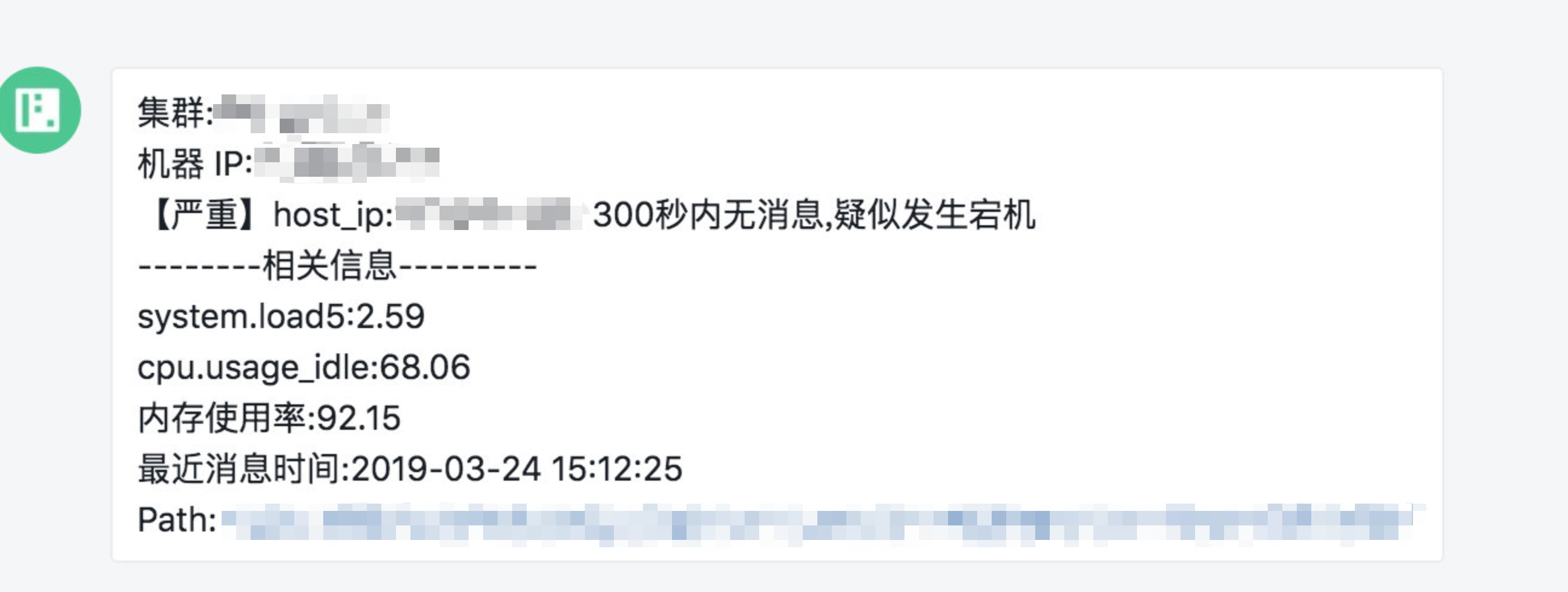
(1)告警方式(邮件、短信、钉钉、微信)
在计算层会将计算结果与阈值进行比较,超过阈值触发告警,让运维提前收到通知,告警消息如下图所示,这样运维可以及时做好应对措施,减少故障的损失大小。
(2)存储(消息队列、DB、文件系统等)
数据存储后,监控大盘(Dashboard)从存储(ElasticSearch、HBase 等)里面查询对应指标的数据就可以查看实时的监控信息,做到对促销活动的商品销量、销售额,机器 CPU、Mem 等有实时监控,运营、运维、开发、领导都可以实时查看并作出对应的措施。
- 让运营知道哪些商品是爆款,哪些店铺成交额最多,如下图所示,哪些商品成交额最高,哪些商品浏览量最多;

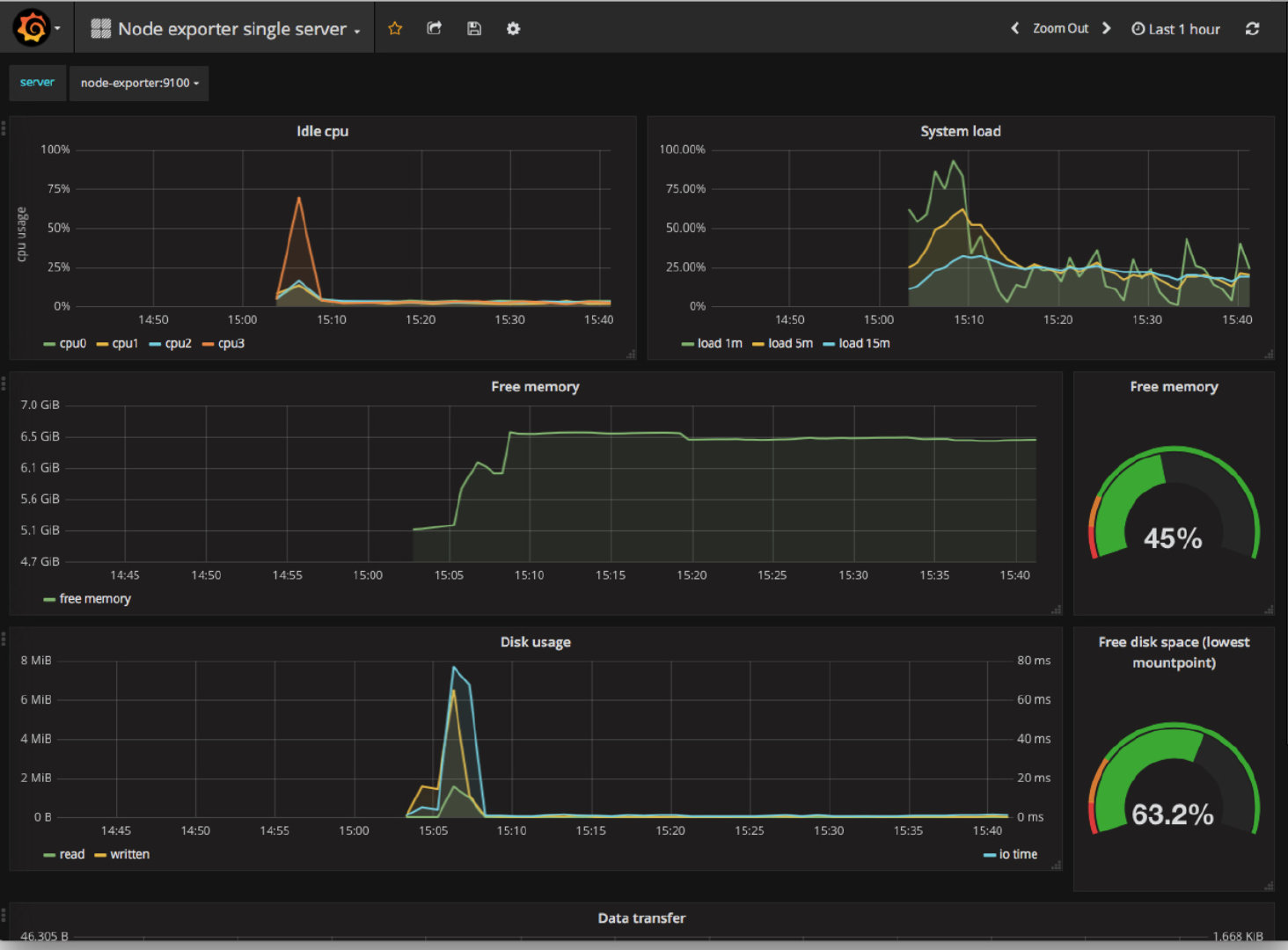
- 让运维可以时刻了解机器的运行状况,如下图所示,出现宕机或者其他不稳定情况可以及时处理;
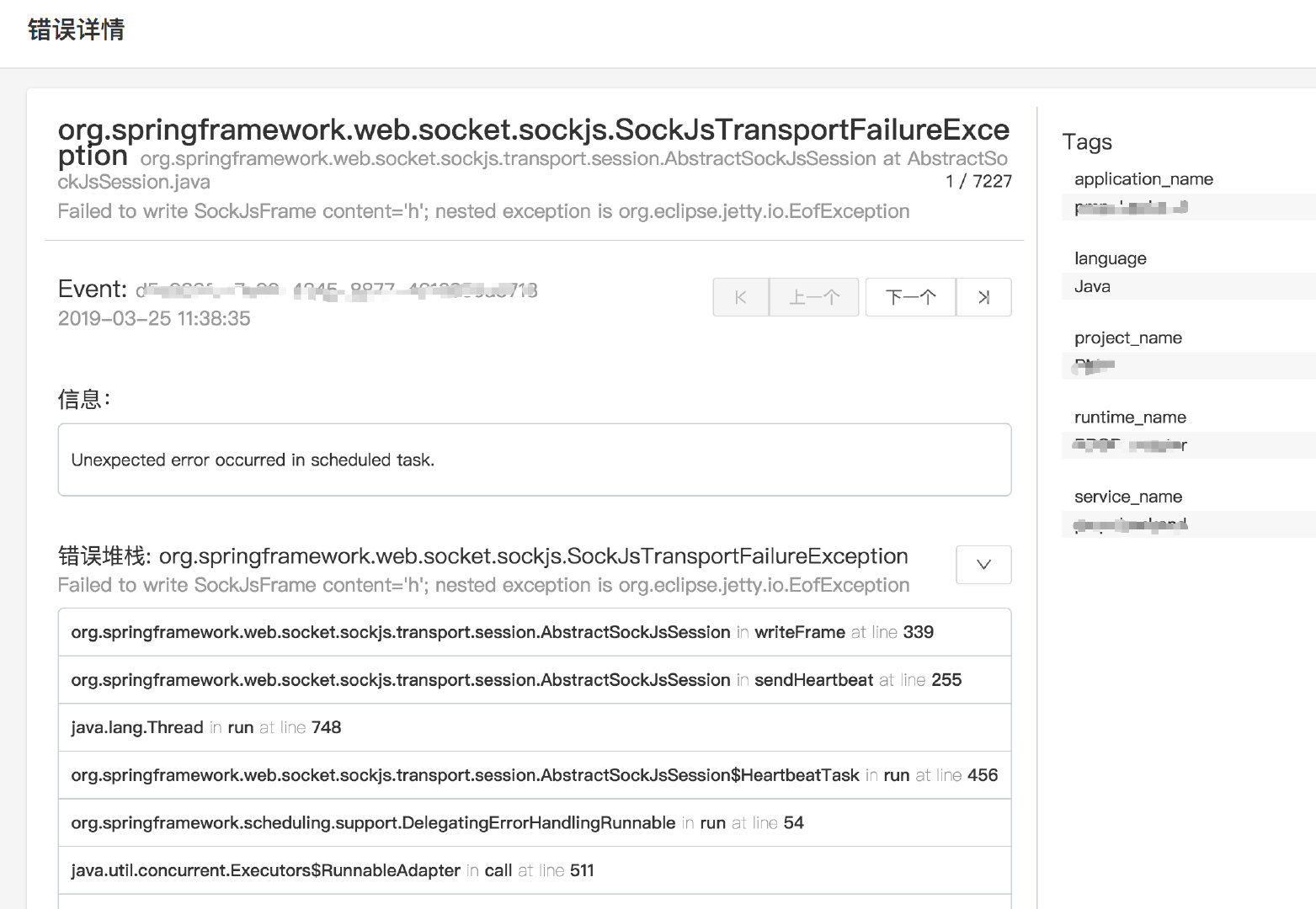
- 让开发知道自己项目运行的情况,从 Error 日志知道出现了哪些 Bug,如下图所示;
- 让领导知道这次促销赚了多少 money,如下图所示。

从数据采集到数据计算再到数据下发,如下图所示,整个流程在上面的场景对实时性要求还是很高的,任何一个地方出现问题都将影响最后的效果!
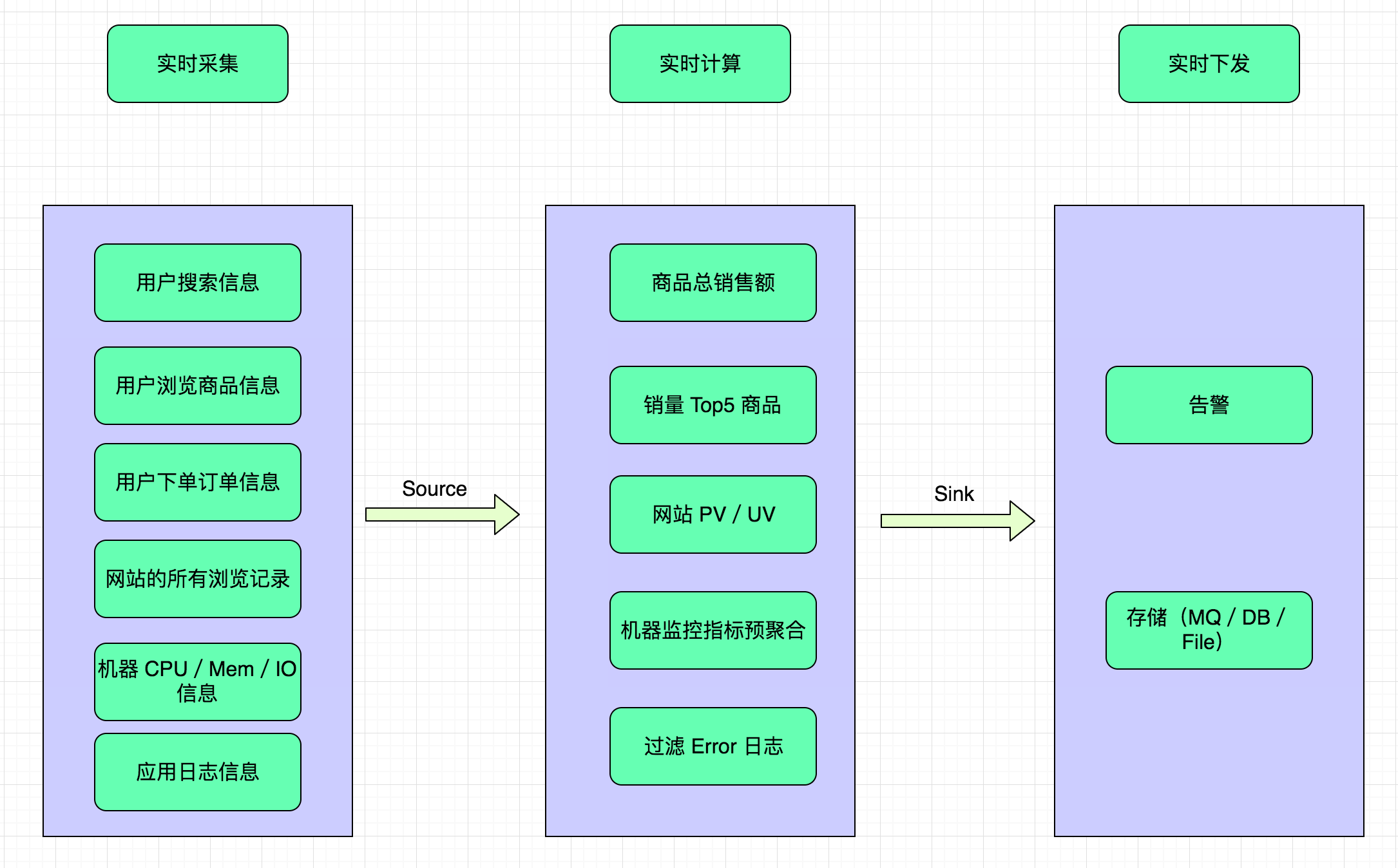
1.1.5 实时计算场景
前面说了这么多场景,这里我们总结一下实时计算常用的场景有哪些呢?比如:
- 交通信号灯数据
- 道路上车流量统计(拥堵状况)
- 公安视频监控
- 服务器运行状态监控
- 金融证券公司实时跟踪股市波动,计算风险价值
- 数据实时 ETL
- 银行或者支付公司涉及金融盗窃的预警
……
另外自己还做过调研,实时计算框架的使用场景有如下这些:
- 业务数据处理,聚合业务数据,统计之类
- 流量日志
- ETL
- 安防这块,公安视频结构化数据,用 Flink 做图片搜索
- 风控,主要处理结构化数据
- 业务告警
- 动态数据监控
总结一下大概有下面这四类,如下图所示:
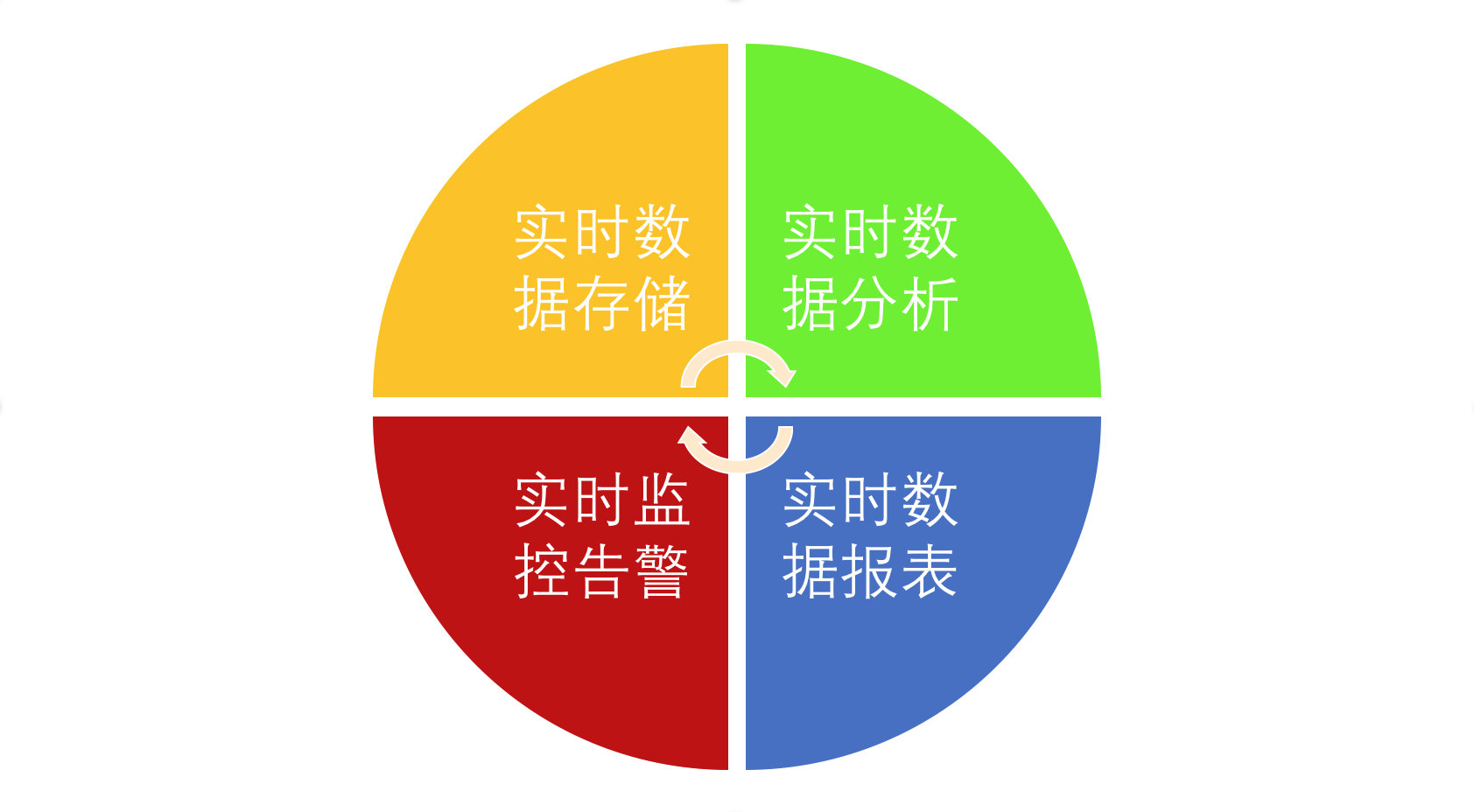
这四类分别是:
- 实时数据存储:实时数据存储的时候做一些微聚合、过滤某些字段、数据脱敏,组建数据仓库,实时 ETL。
- 实时数据分析:实时数据接入机器学习框架(TensorFlow)或者一些算法进行数据建模、分析,然后动态的给出商品推荐、广告推荐
- 实时监控告警:金融相关涉及交易、实时风控、车流量预警、服务器监控告警、应用日志告警
- 实时数据报表:活动营销时销售额/销售量大屏,TopN 商品
说到实时计算,这里不得不讲一下它与传统的离线计算之间的区别!
1.1.6 离线计算 vs 实时计算
再讲离线计算和实时计算这两个区别之前,我们先来看看流处理和批处理。
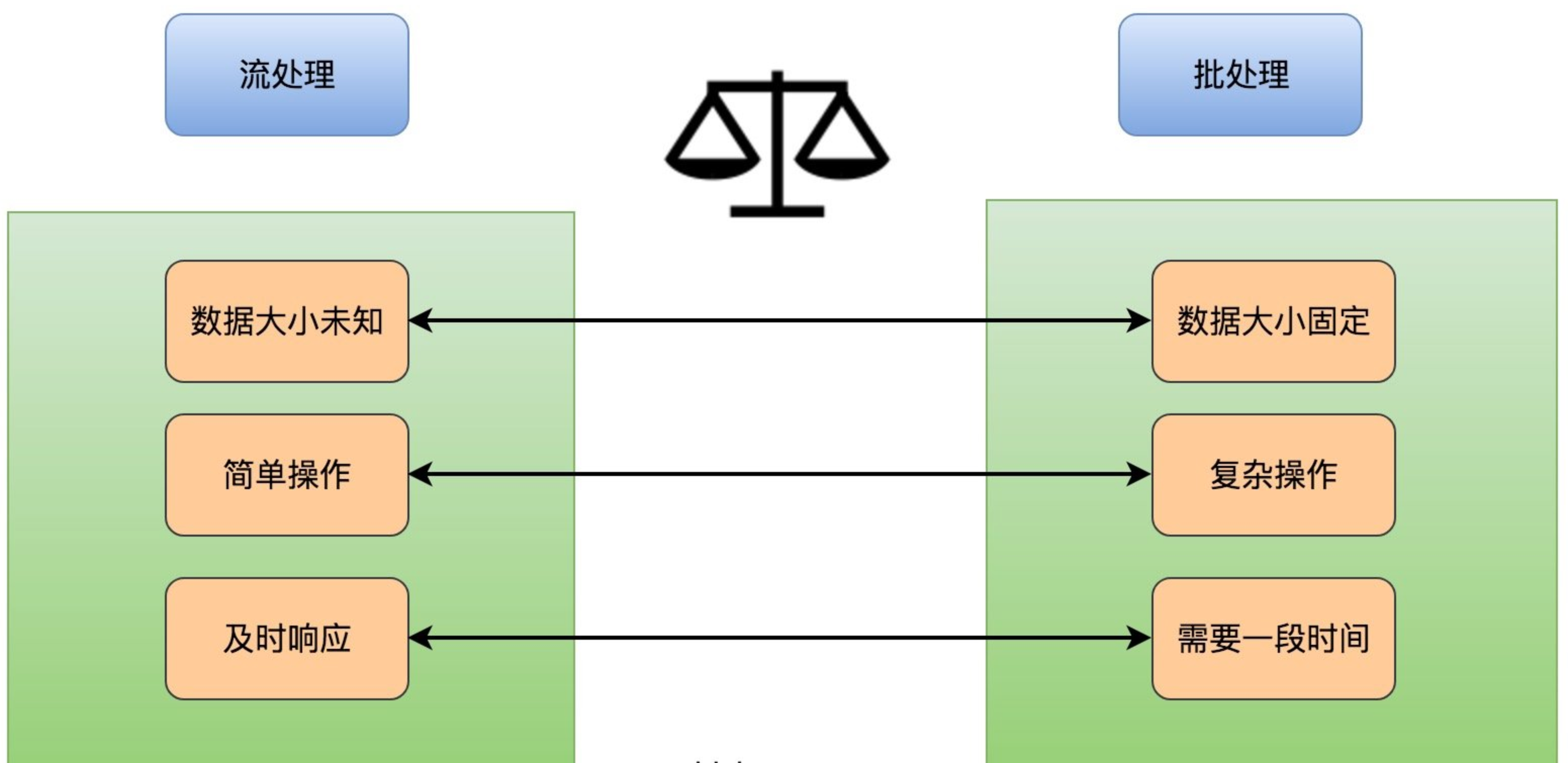
流处理与批处理
流处理是一种重要的大数据处理手段,其主要特点是其处理的数据是源源不断且实时到来的。批处理历史比较悠久,而且使用的场景比较多,其主要操作的是大容量的静态数据集,并在计算过程完成后返回结果。它们之间的区别如下图所示:
看完流处理与批处理这两者的区别之后,我们来抽象一下前面内容的场景需求计算流程(实时计算)如下图所示:
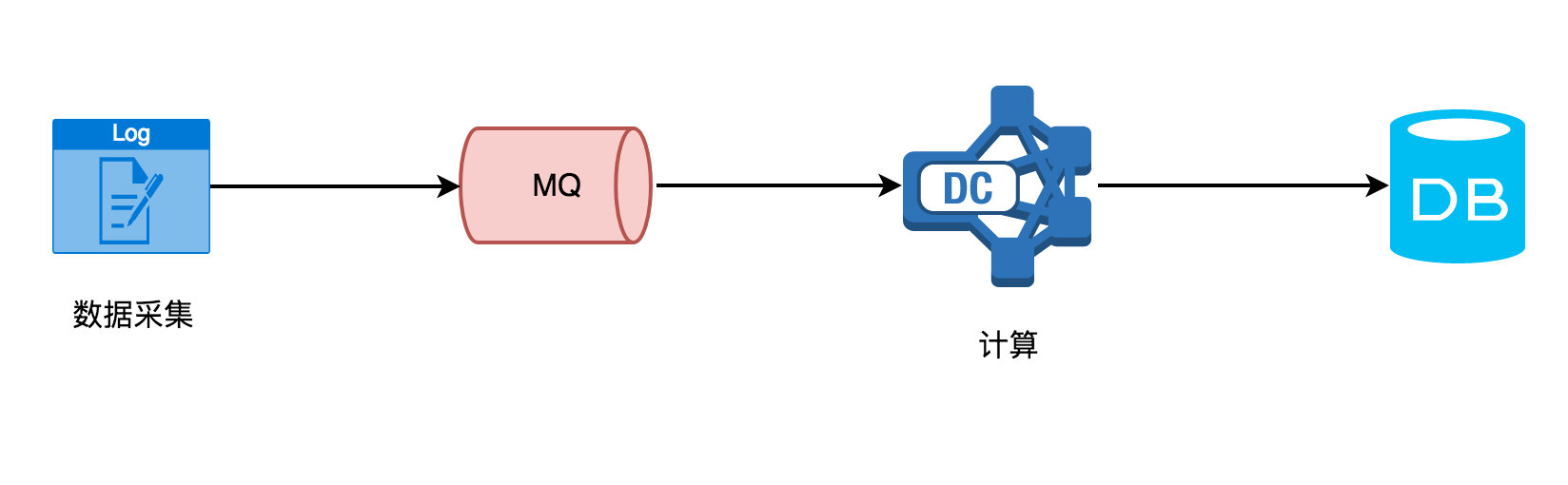
实时计算需要不断的从 MQ 中读取采集的数据,然后处理计算后往 DB 里存储,在计算这层你无法感知到会有多少数据量过来、要做一些简单的操作(过滤、聚合等)、及时将数据下发。然而传统的离线计算却如下图所示:
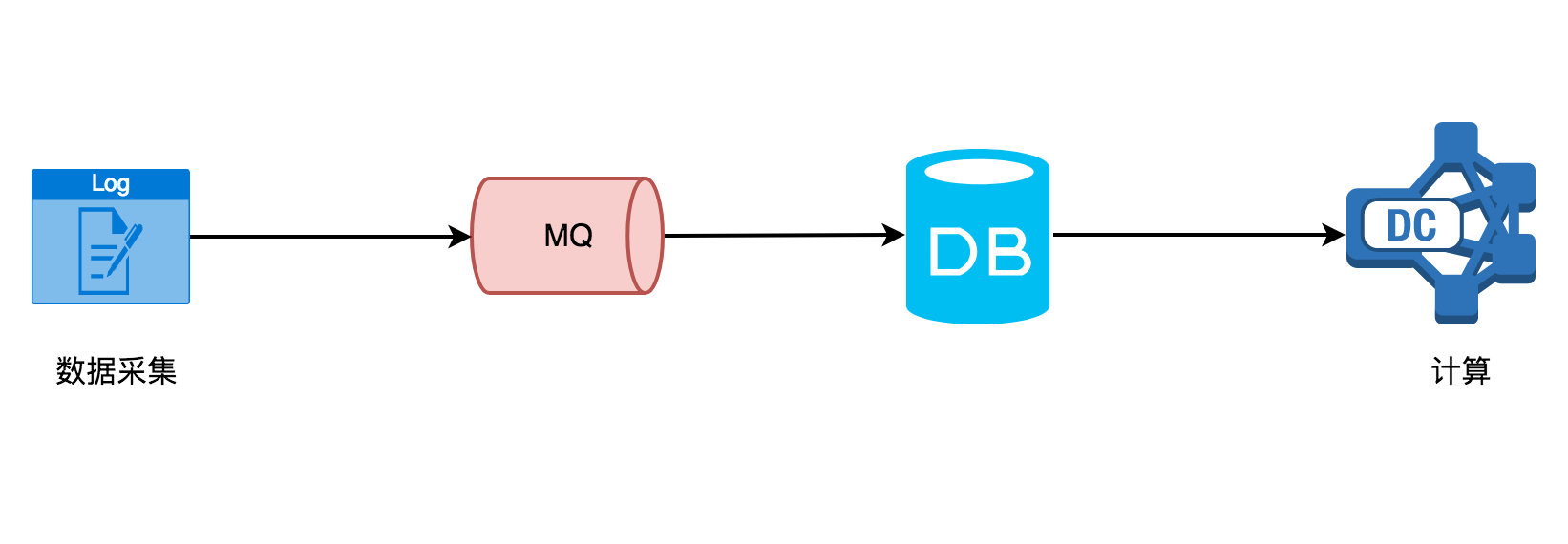
在计算这层,它从 DB(不限 MySQL,还有其他的存储介质)里面读取数据,该数据一般就是固定的(前一天、前一星期、前一个月),然后再做一些复杂的计算或者统计分析,最后生成可供直观查看的报表(dashboard)。
离线计算的特点
离线计算一般有下面这些特点:
- 数据量大且时间周期长(一天、一星期、一个月、半年、一年)
- 在大量数据上进行复杂的批量计算操作
- 数据在计算之前已经固定,不再会发生变化
- 能够方便的查询批量计算的结果
实时计算的特点
在大数据中与离线计算对应的则是实时计算,那么实时计算有什么特点呢?由于应用场景的各不相同,所以这两种计算引擎接收数据的方式也不太一样:离线计算的数据是固定的(不再会发生变化),通常离线计算的任务都是定时的,如:每天晚上 0 点的时候定时计算前一天的数据,生成报表;然而实时计算的数据源却是流式的。
这里我不得不讲讲什么是流式数据呢?我的理解是比如你在淘宝上下单了某个商品或者点击浏览了某件商品,你就会发现你的页面立马就会给你推荐这种商品的广告和类似商品的店铺,这种就是属于实时数据处理然后作出相关推荐,这类数据需要不断的从你在网页上的点击动作中获取数据,之后进行实时分析然后给出推荐。
流式数据的特点
流式数据一般有下面这些特点:
- 数据实时到达
- 数据到达次序独立,不受应用系统所控制
- 数据规模大且无法预知容量
- 原始数据一经处理,除非特意保存,否则不能被再次取出处理,或者再次提取数据代价昂贵
通过上面的内容可以总结实时计算与离线计算的对比如下图所示:

实时计算的优势
实时计算一时爽,一直实时计算一直爽,对于持续生成最新数据的场景,采用流数据处理是非常有利的。例如,再监控服务器的一些运行指标的时候,能根据采集上来的实时数据进行判断,当超出一定阈值的时候发出警报,进行提醒作用。再如通过处理流数据生成简单的报告,如五分钟的窗口聚合数据平均值。复杂的事情还有在流数据中进行数据多维度关联、聚合、筛选,从而找到复杂事件中的根因。更为复杂的是做一些复杂的数据分析操作,如应用机器学习算法,然后根据算法处理后的数据结果提取出有效的信息,作出、给出不一样的推荐内容,让不同的人可以看见不同的网页(千人千面)。
1.1.7 实时计算面临的挑战
虽然实时计算有这么多好处,但是要使用实时计算也会面临很多挑战,比如下面这些:
- 数据处理唯一性(如何保证数据只处理一次?至少一次?最多一次?)
- 数据处理的及时性(采集的实时数据量太大的话可能会导致短时间内处理不过来,如何保证数据能够及时的处理,不出现数据堆积?)
- 数据处理层和存储层的可扩展性(如何根据采集的实时数据量的大小提供动态扩缩容?)
- 数据处理层和存储层的容错性(如何保证数据处理层和存储层高可用,出现故障时数据处理层和存储层服务依旧可用?)
因为各种需求,也就造就了现在不断出现实时计算框架,在 1.2 节中将重磅介绍如今最火的实时计算框架 —— Flink,在 1.3 节中会对比介绍 Spark Streaming、Structured Streaming 和 Storm 之间的区别。
1.1.8 小结与反思
本节从实时计算的需求作为切入点,然后分析该如何去完成这种实时计算的需求,从而得知整个过程包括数据采集、数据计算、数据存储等,接着总结了实时计算场景的类型。最后开始介绍离线计算与实时计算的区别,并提出了实时计算可能带来的挑战。你们公司有文中所讲的类似需求吗?你是怎么解决的呢?


