前言
之前其实在 《从0到1学习Flink》—— 如何自定义 Data Sink ? 文章中其实已经写了点将数据写入到 MySQL,但是一些配置化的东西当时是写死的,不能够通用,最近知识星球里有朋友叫我: 写个从 kafka 中读取数据,经过 Flink 做个预聚合,然后创建数据库连接池将数据批量写入到 mysql 的例子。

于是才有了这篇文章,更多提问和想要我写的文章可以在知识星球里像我提问,我会根据提问及时回答和尽可能作出文章的修改。
准备
你需要将这两个依赖添加到 pom.xml 中
1
2
3
4
5
| <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.34</version>
</dependency>
|
读取 kafka 数据
这里我依旧用的以前的 student 类,自己本地起了 kafka 然后造一些测试数据,这里我们测试发送一条数据则 sleep 10s,意味着往 kafka 中一分钟发 6 条数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| package com.zhisheng.connectors.mysql.utils;
import com.zhisheng.common.utils.GsonUtil;
import com.zhisheng.connectors.mysql.model.Student;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaUtil {
public static final String broker_list = "localhost:9092";
public static final String topic = "student";
public static void writeToKafka() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", broker_list);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer<String, String>(props);
for (int i = 1; i <= 100; i++) {
Student student = new Student(i, "zhisheng" + i, "password" + i, 18 + i);
ProducerRecord record = new ProducerRecord<String, String>(topic, null, null, GsonUtil.toJson(student));
producer.send(record);
System.out.println("发送数据: " + GsonUtil.toJson(student));
Thread.sleep(10 * 1000);
}
producer.flush();
}
public static void main(String[] args) throws InterruptedException {
writeToKafka();
}
}
|
从 kafka 中读取数据,然后序列化成 student 对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "metric-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
SingleOutputStreamOperator<Student> student = env.addSource(new FlinkKafkaConsumer011<>(
"student",
new SimpleStringSchema(),
props)).setParallelism(1)
.map(string -> GsonUtil.fromJson(string, Student.class));
|
因为 RichSinkFunction 中如果 sink 一条数据到 mysql 中就会调用 invoke 方法一次,所以如果要实现批量写的话,我们最好在 sink 之前就把数据聚合一下。那这里我们开个一分钟的窗口去聚合 Student 数据。
1
2
3
4
5
6
7
8
9
10
| student.timeWindowAll(Time.minutes(1)).apply(new AllWindowFunction<Student, List<Student>, TimeWindow>() {
@Override
public void apply(TimeWindow window, Iterable<Student> values, Collector<List<Student>> out) throws Exception {
ArrayList<Student> students = Lists.newArrayList(values);
if (students.size() > 0) {
System.out.println("1 分钟内收集到 student 的数据条数是:" + students.size());
out.collect(students);
}
}
});
|
写入数据库
这里使用 DBCP 连接池连接数据库 mysql,pom.xml 中添加依赖:
1
2
3
4
5
| <dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
|
如果你想使用其他的数据库连接池请加入对应的依赖。
这里将数据写入到 MySQL 中,依旧是和之前文章一样继承 RichSinkFunction 类,重写里面的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
| package com.zhisheng.connectors.mysql.sinks;
import com.zhisheng.connectors.mysql.model.Student;
import org.apache.commons.dbcp2.BasicDataSource;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.util.List;
public class SinkToMySQL extends RichSinkFunction<List<Student>> {
PreparedStatement ps;
BasicDataSource dataSource;
private Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
dataSource = new BasicDataSource();
connection = getConnection(dataSource);
String sql = "insert into Student(id, name, password, age) values(?, ?, ?, ?);";
ps = this.connection.prepareStatement(sql);
}
@Override
public void close() throws Exception {
super.close();
if (connection != null) {
connection.close();
}
if (ps != null) {
ps.close();
}
}
@Override
public void invoke(List<Student> value, Context context) throws Exception {
for (Student student : value) {
ps.setInt(1, student.getId());
ps.setString(2, student.getName());
ps.setString(3, student.getPassword());
ps.setInt(4, student.getAge());
ps.addBatch();
}
int[] count = ps.executeBatch();
System.out.println("成功了插入了" + count.length + "行数据");
}
private static Connection getConnection(BasicDataSource dataSource) {
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/test");
dataSource.setUsername("root");
dataSource.setPassword("root123456");
dataSource.setInitialSize(10);
dataSource.setMaxTotal(50);
dataSource.setMinIdle(2);
Connection con = null;
try {
con = dataSource.getConnection();
System.out.println("创建连接池:" + con);
} catch (Exception e) {
System.out.println("-----------mysql get connection has exception , msg = " + e.getMessage());
}
return con;
}
}
|
核心类 Main
核心程序如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| public class Main {
public static void main(String[] args) throws Exception{
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "metric-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
SingleOutputStreamOperator<Student> student = env.addSource(new FlinkKafkaConsumer011<>(
"student",
new SimpleStringSchema(),
props)).setParallelism(1)
.map(string -> GsonUtil.fromJson(string, Student.class));
student.timeWindowAll(Time.minutes(1)).apply(new AllWindowFunction<Student, List<Student>, TimeWindow>() {
@Override
public void apply(TimeWindow window, Iterable<Student> values, Collector<List<Student>> out) throws Exception {
ArrayList<Student> students = Lists.newArrayList(values);
if (students.size() > 0) {
System.out.println("1 分钟内收集到 student 的数据条数是:" + students.size());
out.collect(students);
}
}
}).addSink(new SinkToMySQL());
env.execute("flink learning connectors kafka");
}
}
|
运行项目
运行 Main 类后再运行 KafkaUtils.java 类!
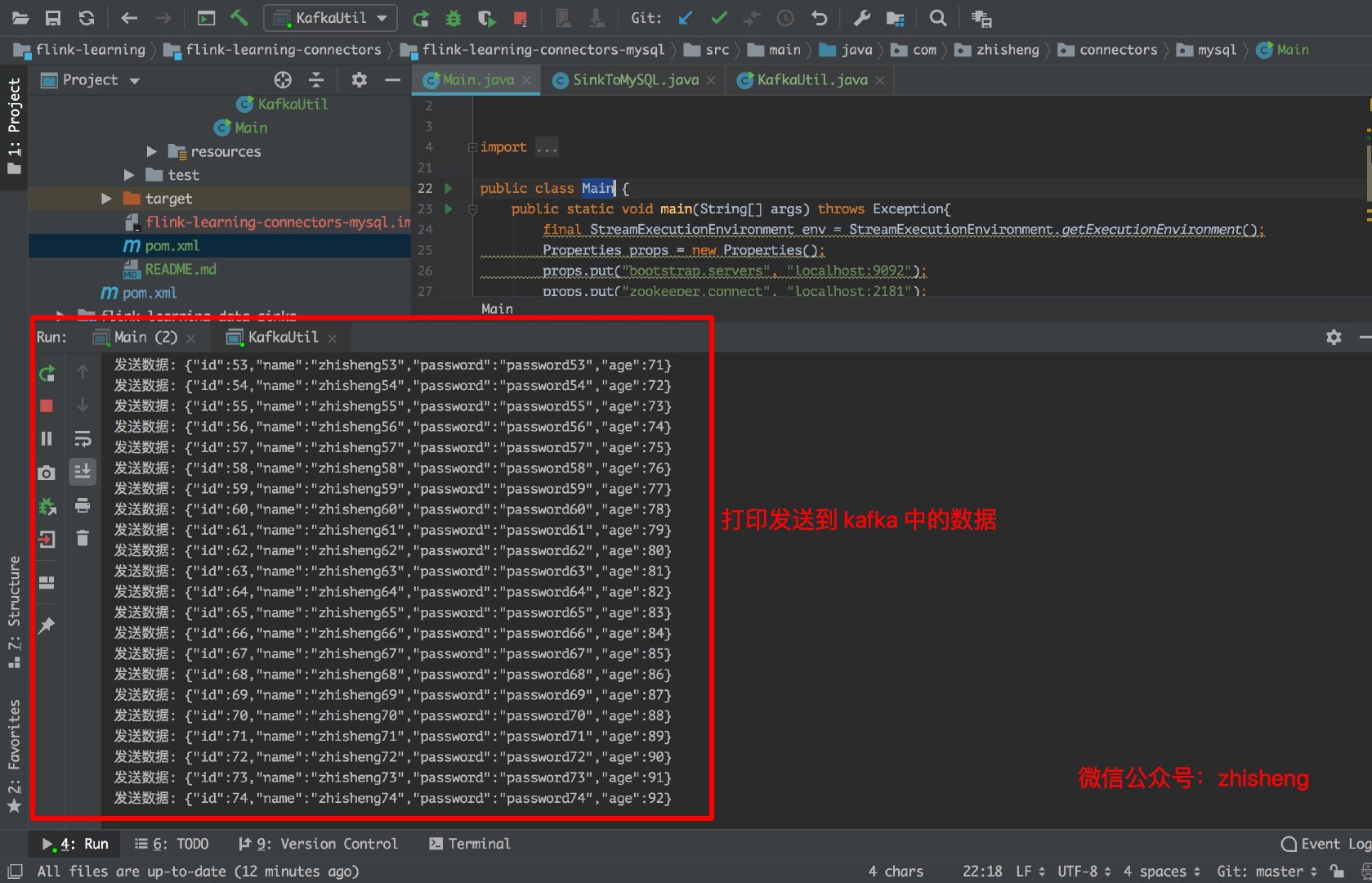
下图是往 Kafka 中发送的数据:
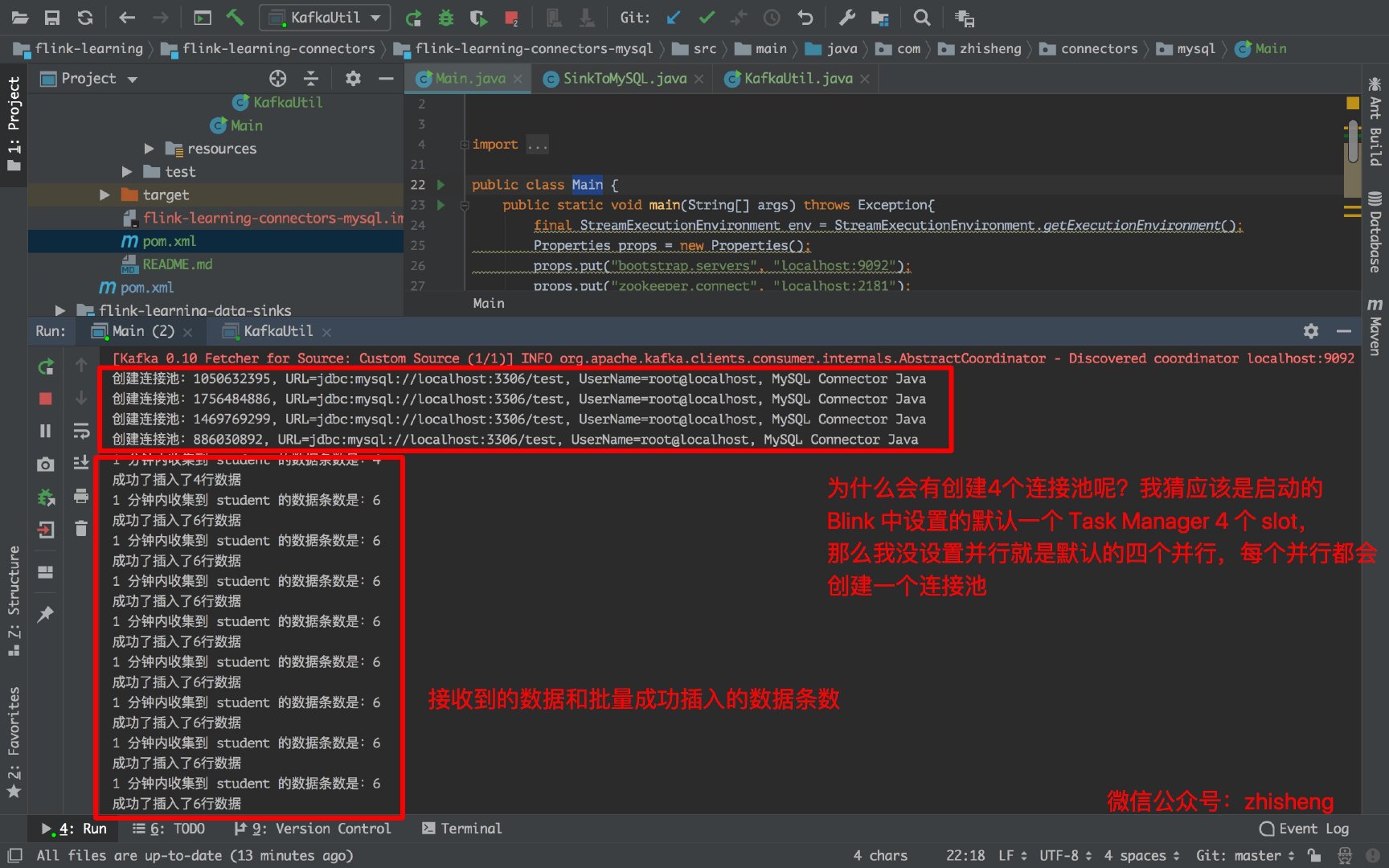
下图是运行 Main 类的日志,会创建 4 个连接池是因为默认的 4 个并行度,你如果在 addSink 这个算子设置并行度为 1 的话就会创建一个连接池:
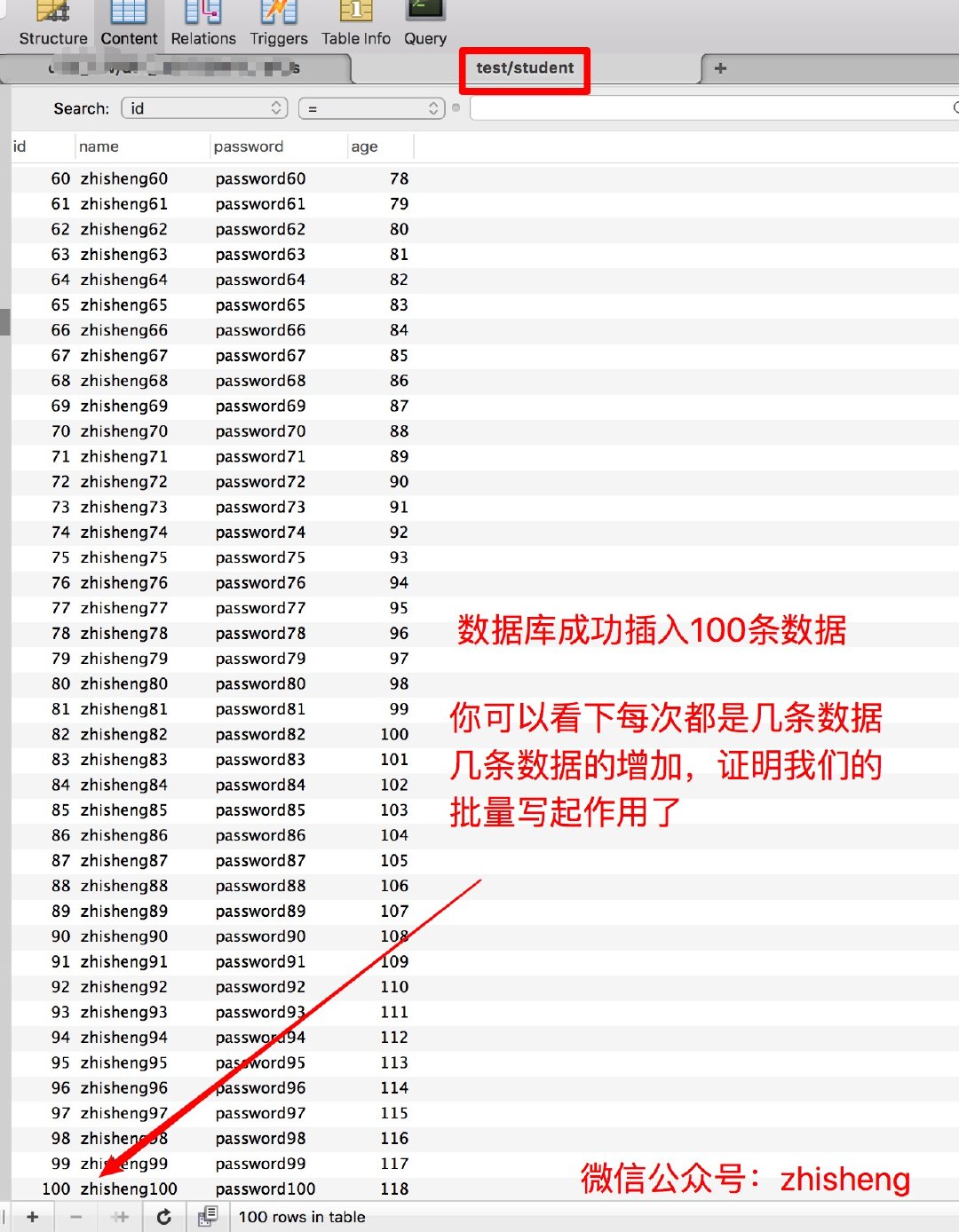
下图是批量插入数据库的结果:
总结
本文从知识星球一位朋友的疑问来写的,应该都满足了他的条件(批量/数据库连接池/写入mysql),的确网上很多的例子都是简单的 demo 形式,都是单条数据就创建数据库连接插入 MySQL,如果要写的数据量很大的话,会对 MySQL 的写有很大的压力。这也是我之前在 《从0到1学习Flink》—— Flink 写入数据到 ElasticSearch 中,数据写 ES 强调过的,如果要提高性能必定要批量的写。就拿我们现在这篇文章来说,如果数据量大的话,聚合一分钟数据达万条,那么这样批量写会比来一条写一条性能提高不知道有多少。
本文原创地址是: http://www.54tianzhisheng.cn/2019/01/15/Flink-MySQL-sink/ , 未经允许禁止转载。
关注我
微信公众号:zhisheng
另外我自己整理了些 Flink 的学习资料,目前已经全部放到微信公众号(zhisheng)了,你可以回复关键字:Flink 即可无条件获取到。另外也可以加我微信 你可以加我的微信:yuanblog_tzs,探讨技术!

更多私密资料请加入知识星球!

专栏介绍
扫码下面专栏二维码可以订阅该专栏

首发地址:http://www.54tianzhisheng.cn/2019/11/15/flink-in-action/
专栏地址:https://gitbook.cn/gitchat/column/5dad4a20669f843a1a37cb4f
Github 代码仓库
https://github.com/zhisheng17/flink-learning/
以后这个项目的所有代码都将放在这个仓库里,包含了自己学习 flink 的一些 demo 和博客。
本文的项目代码在 https://github.com/zhisheng17/flink-learning/tree/master/flink-learning-connectors/flink-learning-connectors-mysql
博客
1、Flink 从0到1学习 —— Apache Flink 介绍
2、Flink 从0到1学习 —— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
3、Flink 从0到1学习 —— Flink 配置文件详解
4、Flink 从0到1学习 —— Data Source 介绍
5、Flink 从0到1学习 —— 如何自定义 Data Source ?
6、Flink 从0到1学习 —— Data Sink 介绍
7、Flink 从0到1学习 —— 如何自定义 Data Sink ?
8、Flink 从0到1学习 —— Flink Data transformation(转换)
9、Flink 从0到1学习 —— 介绍 Flink 中的 Stream Windows
10、Flink 从0到1学习 —— Flink 中的几种 Time 详解
11、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 ElasticSearch
12、Flink 从0到1学习 —— Flink 项目如何运行?
13、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Kafka
14、Flink 从0到1学习 —— Flink JobManager 高可用性配置
15、Flink 从0到1学习 —— Flink parallelism 和 Slot 介绍
16、Flink 从0到1学习 —— Flink 读取 Kafka 数据批量写入到 MySQL
17、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RabbitMQ
18、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HBase
19、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HDFS
20、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Redis
21、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Cassandra
22、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Flume
23、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 InfluxDB
24、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RocketMQ
25、Flink 从0到1学习 —— 你上传的 jar 包藏到哪里去了
26、Flink 从0到1学习 —— 你的 Flink job 日志跑到哪里去了
27、阿里巴巴开源的 Blink 实时计算框架真香
28、Flink 从0到1学习 —— Flink 中如何管理配置?
29、Flink 从0到1学习—— Flink 不可以连续 Split(分流)?
30、Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
31、Flink 架构、原理与部署测试
32、为什么说流处理即未来?
33、OPPO 数据中台之基石:基于 Flink SQL 构建实时数据仓库
34、流计算框架 Flink 与 Storm 的性能对比
35、Flink状态管理和容错机制介绍
36、Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
37、360深度实践:Flink与Storm协议级对比
38、如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
39、Apache Flink 1.9 重大特性提前解读
40、Flink 全网最全资源(视频、博客、PPT、入门、实战、源码解析、问答等持续更新)
41、Flink 灵魂两百问,这谁顶得住?
42、Flink 从0到1学习 —— 如何使用 Side Output 来分流?
43、你公司到底需不需要引入实时计算引擎?
44、一文让你彻底了解大数据实时计算引擎 Flink
源码解析
1、Flink 源码解析 —— 源码编译运行
2、Flink 源码解析 —— 项目结构一览
3、Flink 源码解析—— local 模式启动流程
4、Flink 源码解析 —— standalone session 模式启动流程
5、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Job Manager 启动
6、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Task Manager 启动
7、Flink 源码解析 —— 分析 Batch WordCount 程序的执行过程
8、Flink 源码解析 —— 分析 Streaming WordCount 程序的执行过程
9、Flink 源码解析 —— 如何获取 JobGraph?
10、Flink 源码解析 —— 如何获取 StreamGraph?
11、Flink 源码解析 —— Flink JobManager 有什么作用?
12、Flink 源码解析 —— Flink TaskManager 有什么作用?
13、Flink 源码解析 —— JobManager 处理 SubmitJob 的过程
14、Flink 源码解析 —— TaskManager 处理 SubmitJob 的过程
15、Flink 源码解析 —— 深度解析 Flink Checkpoint 机制
16、Flink 源码解析 —— 深度解析 Flink 序列化机制
17、Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
18、Flink Metrics 源码解析 —— Flink-metrics-core
19、Flink Metrics 源码解析 —— Flink-metrics-datadog
20、Flink Metrics 源码解析 —— Flink-metrics-dropwizard
21、Flink Metrics 源码解析 —— Flink-metrics-graphite
22、Flink Metrics 源码解析 —— Flink-metrics-influxdb
23、Flink Metrics 源码解析 —— Flink-metrics-jmx
24、Flink Metrics 源码解析 —— Flink-metrics-slf4j
25、Flink Metrics 源码解析 —— Flink-metrics-statsd
26、Flink Metrics 源码解析 —— Flink-metrics-prometheus
26、Flink Annotations 源码解析

27、Flink 源码解析 —— 如何获取 ExecutionGraph ?
28、大数据重磅炸弹——实时计算框架 Flink
29、Flink Checkpoint-��轻量级分布式快照
30、Flink Clients 源码解析



