
如何实现呢?
前言
在上一篇博客中,我们对欺诈检测引擎的目标和所需要的功能进行了描述,我们还描述了如何基于可修改的规则而不是使用硬编码的 KeysExtractor 实现 Flink 应用程序的数据自定义分区。
我们在上篇博客中特意省略了有关如何初始化应用的规则以及如何在作业运行时更新的细节,在本文我们将详细的介绍这些细节,你将学习如何将上篇博客中描述的数据分区防御与动态配置结合使用,当这两种模式结合使用的时候,可以省去重新编译代码和重新部署 Flink 作业的需要,从而可以应对多种业务场景逻辑修改的情况。
广播规则
首先让我们看看预定义的数据处理代码:
1 | DataStream<Alert> alerts = |
DynamicKeyFunction 函数提供动态数据分区,同时 DynamicAlertFunction 函数负责执行处理数据的主要逻辑并根据已定义的规则发动告警消息。
在上篇文中中简化了用例,并假定已预先初始化了所应用的规则集数据,并可以通过 DynamicKeyFunction 的 List<Rules> 访问这些规则:
1 | public class DynamicKeyFunction |
显然,在初始化阶段,可以直接在 Flink Job 的代码内部添加规则到此列表(创建List对象;使用它的add方法)。这样做的主要缺点是,每次修改规则后都需要重新编译作业。在真实的欺诈检测系统中,规则会经常更改,因此从业务和运营需求的角度来看,使此方法不可接受,需要一种不同的方法。
接下来,让我们看一下在上一篇文章中介绍的示例规则定义:

上一篇文章介绍了使用 DynamicKeyFunction提取数据含 groupingKeyNames 里面字段组成数据分组 key 的方法。此规则第二部分中的参数由 DynamicAlertFunction 使用:它们定义了所执行操作的实际逻辑及其参数(例如告警触发限制)。这意味着相同的规则必须同时存在于DynamicKeyFunction和DynamicAlertFunction。
下图展示了我们正在构建的系统的最终工作图:
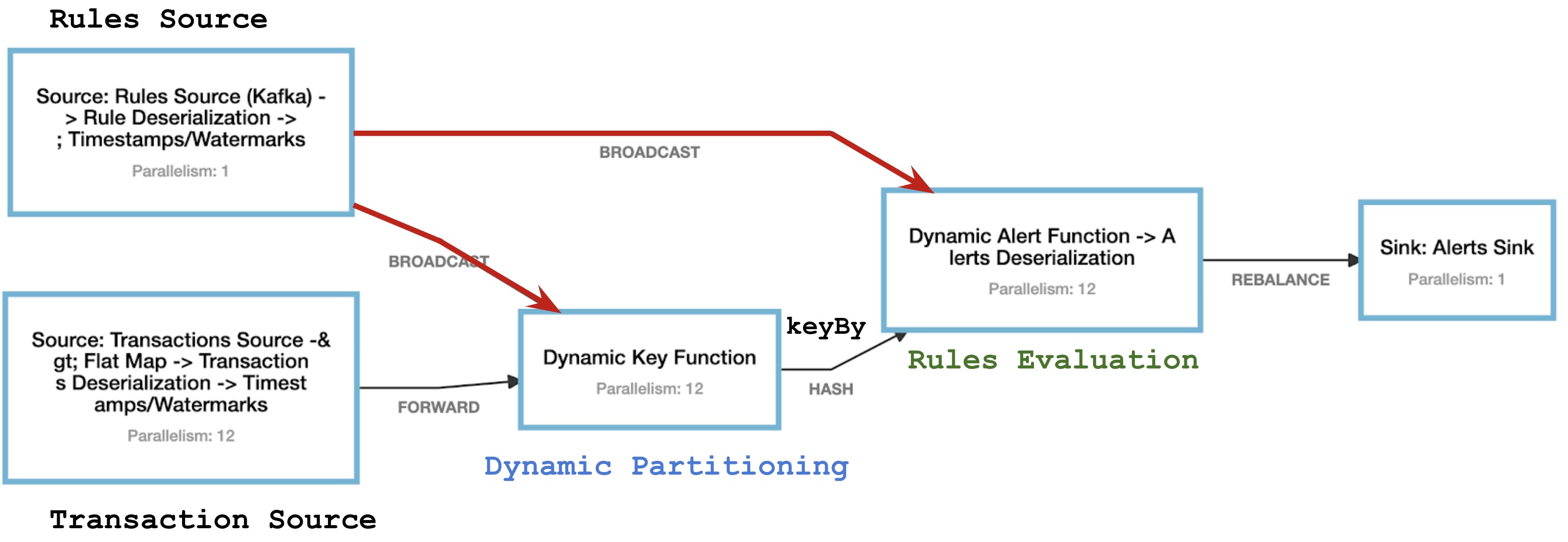
上图的主要模块是:
- Transaction Source:Flink 作业的 Source 端,它会并行的消费 Kafka 中的金融交易流数据
- **Dynamic Key Function:动态的提取数据分区的 key。随后的
keyBy函数会将动态的 key 值进行 hash,并在后续运算符的所有并行实例之间相应地对数据进行分区。 - Dynamic Alert Function:累积窗口中的数据,并基于该窗口创建告警。
Apache Flink 内部的数据交换
上面的作业图还展示了运算符之间的各种数据交换模式,为了了解广播模式是如何工作的,我们先来看一下 Apache Flink 在分布式运行时存在哪些消息传播方法:
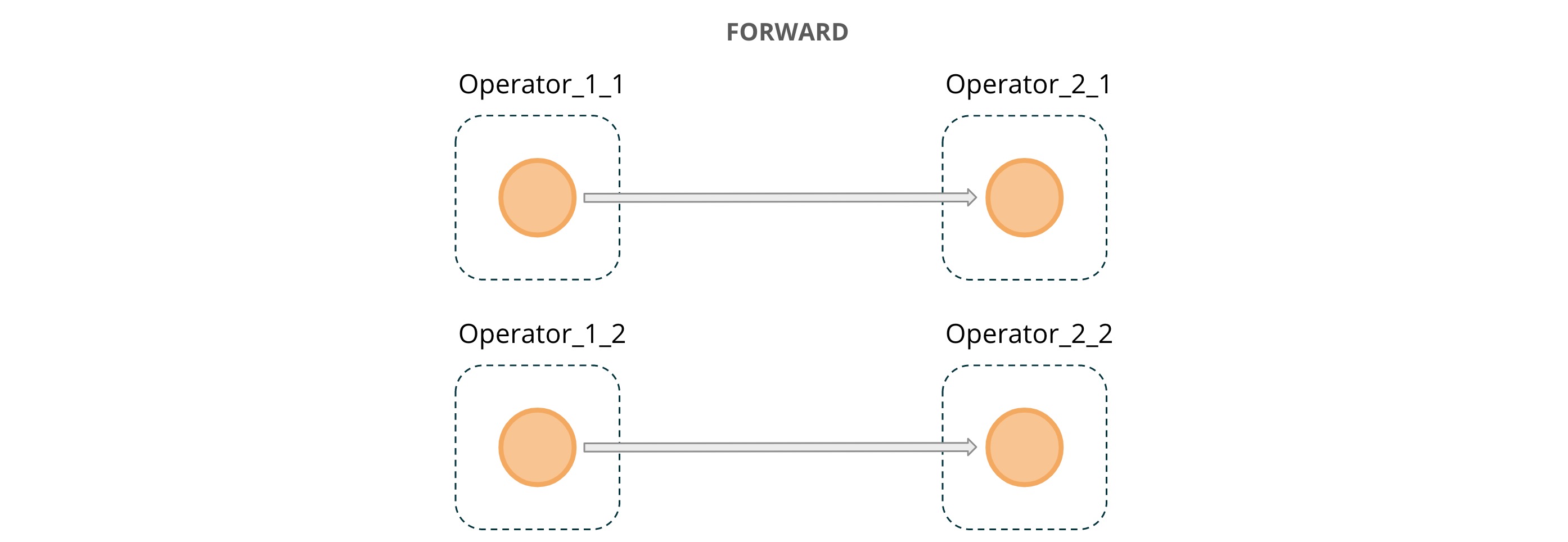
FORWARD:上图中 Transaction Source 后的 FORWARD 意味着每个 Transaction Source 的并行度实例消费到的数据都将精确的传输到后面的 DynamicKeyFunction 运算符的每个实例。它还表示两个连接的运算符处于相同的并行度,这种模式如下图所示:
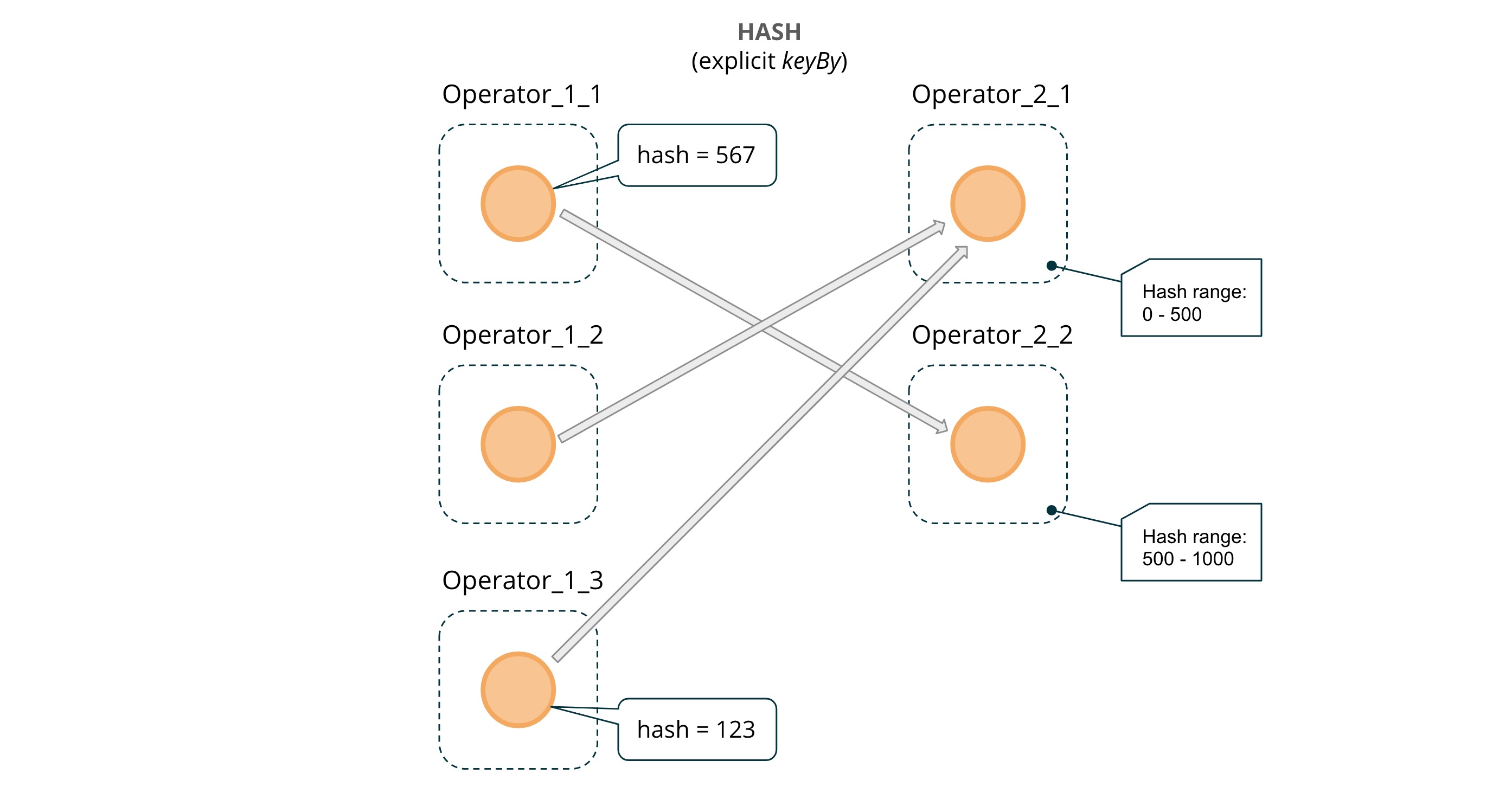
HASH:DynamicKeyFunction 和 DynamicAlertFunction 之间的 HASH 意味着每条消息都会计算一个哈希值,并且消息会在下一个运算符的所有可用并行度之间均匀分配,这种连接一般是通过 keyBy 算子。
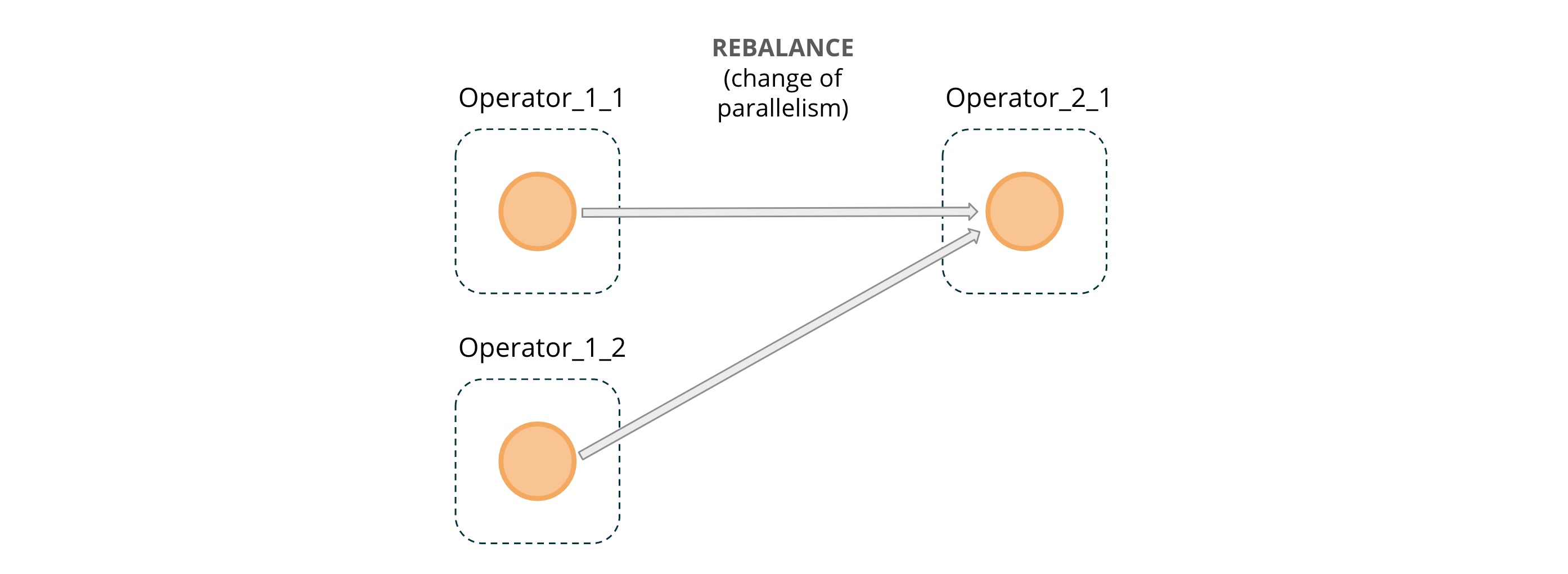
REBALANCE:这种情况下一般是手动的调用 rebalance() 函数或者并行度发生改变导致的,这样会导致数据以循环的方式重新分区,有助于某些情况喜爱的数据倾斜。
BROADCAST:在本文图二中的欺诈检测作业图中包含了一个 Rules Source,它会从 Kafka 中消费规则数据,然后通过 BROADCAST 的通道将规则数据发动到处理实时数据流的算子中去。与在运算符之间传输数据的其他方法(例如 forward、hash、rebalence,这三种仅会将数据发到下游运算符的某个并行度中去)不同,broadcast 可以使得每条消息都会在下游所有的并行度中处理。broadcast 适用于需要影响所有消息处理的任务,而不管消息的 key 或者 Source 的分区是多少。
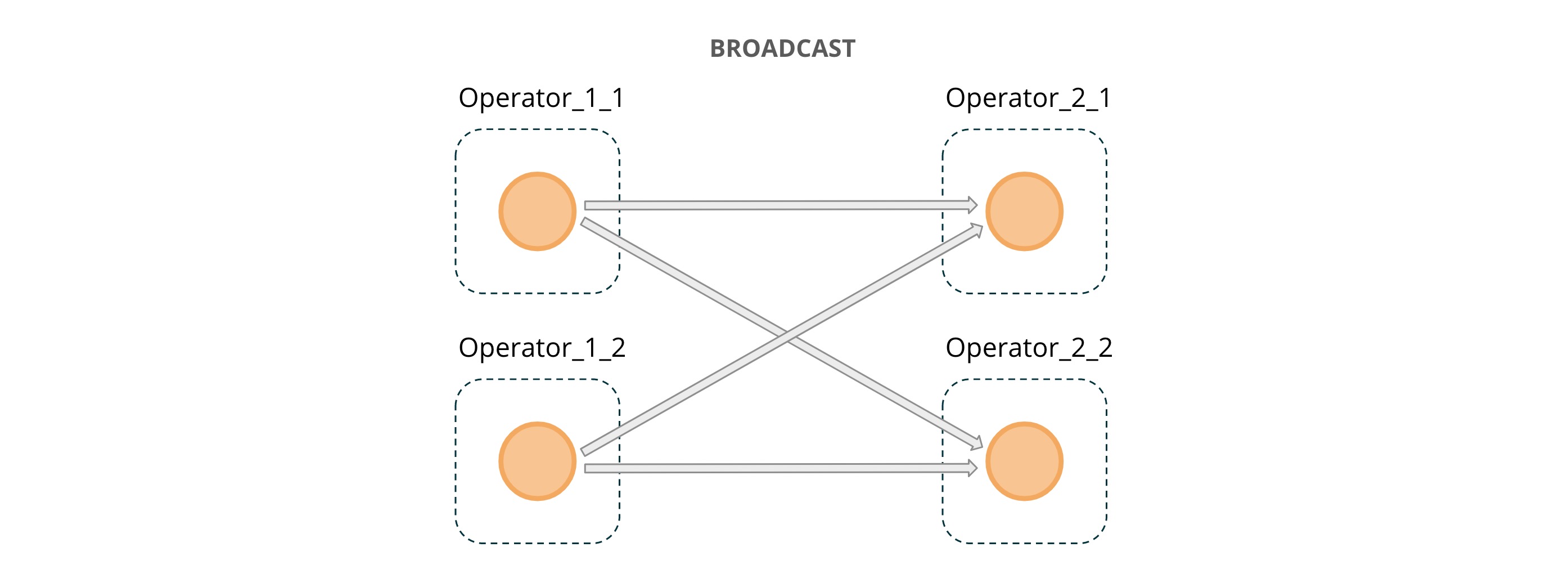
广播状态
为了使用规则数据流,我们需要将其连接到主数据流:
1 | // Streams setup |
如您所见,可以通过调用broadcast方法并指定状态描述符,从任何常规流中创建广播流。在处理主数据流的事件时需要存储和查找广播的数据,因此,Flink 始终根据此状态描述符自动创建相应的广播状态。这与你在使用其他的状态类型不一样,那些是需要在 open 方法里面对其进行初始化。另请注意,广播状态始终是 KV 格式(MapState)。
1 | public static final MapStateDescriptor<Integer, Rule> RULES_STATE_DESCRIPTOR = |
连接rulesStream后会导致 ProcessFunction 的内部发生某些变化。上一篇文章以稍微简化的方式介绍了ProcessFunction。但是 DynamicKeyFunction实际上是一个BroadcastProcessFunction。
1 | public abstract class BroadcastProcessFunction<IN1, IN2, OUT> { |
不同的是,添加processBroadcastElement 了方法,该方法是用于处理到达的广播规则流。以下新版本的DynamicKeyFunction 函数允许在 processElement 方法里面中动态的修改数据分发的 key 列表:
1 | public class DynamicKeyFunction |
在上面的代码中,processElement()接收金融交易数据,并在 processBroadcastElement() 接收规则更新数据。创建新规则时,将如上面广播流的那张图所示进行分配,并会保存在所有使用 processBroadcastState 运算符的并行实例中。我们使用规则的 ID 作为存储和引用单个规则的 key。我们遍历动态更新的广播状态中的数据,而不是遍历硬编码的 List<Rules> 。
在将规则存储在广播 MapState 中时,DynamicAlertFunction 遵循相同的逻辑。如第 1 部分中所述,通过processElement 方法输入的每条消息均应按照一个特定规则进行处理,并通过 DynamicKeyFunction 对其进行“预标记”并带有相应的ID。我们需要做的就是使用提供的 ID 从 BroadcastState 中检索相应规则,并根据该规则所需的逻辑对其进行处理。在此阶段,我们还将消息添加到内部函数状态,以便在所需的数据时间窗口上执行计算。我们将在下一篇文章中考虑如何实现这一点。
总结
在本文,我们继续研究了使用 Apache Flink 构建的欺诈检测系统的用例。我们研究了在并行运算符实例之间分配数据的不同方式,最重要的是广播状态。我们演示了如何通过广播状态提供的功能来组合和增强动态分区。在运行时发送动态更新的功能是 Apache Flink 的强大功能,适用于多种其他使用场景,例如控制状态(清除/插入/修复),运行 A / B 实验或执行 ML 模型系数的更新。
本篇文章属于翻译文章,作者:zhisheng
原文地址:http://www.54tianzhisheng.cn/2021/01/23/Flink-Fraud-Detection-engine-2/
英文作者:alex_fedulov
英文原文地址:https://flink.apache.org/news/2020/03/24/demo-fraud-detection-2.html
关注我
微信公众号:zhisheng
另外我自己整理了些 Flink 的学习资料,目前已经全部放到微信公众号(zhisheng)了,你可以回复关键字:Flink 即可无条件获取到。另外也可以加我微信 你可以加我的微信:yuanblog_tzs,探讨技术!

更多私密资料请加入知识星球!

专栏介绍
首发地址:http://www.54tianzhisheng.cn/2019/11/15/flink-in-action/
专栏地址:https://gitbook.cn/gitchat/column/5dad4a20669f843a1a37cb4f
Github 代码仓库
https://github.com/zhisheng17/flink-learning/
以后这个项目的所有代码都将放在这个仓库里,包含了自己学习 flink 的一些 demo 和博客
博客
1、Flink 从0到1学习 —— Apache Flink 介绍
2、Flink 从0到1学习 —— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
3、Flink 从0到1学习 —— Flink 配置文件详解
4、Flink 从0到1学习 —— Data Source 介绍
5、Flink 从0到1学习 —— 如何自定义 Data Source ?
6、Flink 从0到1学习 —— Data Sink 介绍
7、Flink 从0到1学习 —— 如何自定义 Data Sink ?
8、Flink 从0到1学习 —— Flink Data transformation(转换)
9、Flink 从0到1学习 —— 介绍 Flink 中的 Stream Windows
10、Flink 从0到1学习 —— Flink 中的几种 Time 详解
11、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 ElasticSearch
12、Flink 从0到1学习 —— Flink 项目如何运行?
13、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Kafka
14、Flink 从0到1学习 —— Flink JobManager 高可用性配置
15、Flink 从0到1学习 —— Flink parallelism 和 Slot 介绍
16、Flink 从0到1学习 —— Flink 读取 Kafka 数据批量写入到 MySQL
17、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RabbitMQ
18、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HBase
19、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HDFS
20、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Redis
21、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Cassandra
22、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Flume
23、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 InfluxDB
24、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RocketMQ
25、Flink 从0到1学习 —— 你上传的 jar 包藏到哪里去了
26、Flink 从0到1学习 —— 你的 Flink job 日志跑到哪里去了
28、Flink 从0到1学习 —— Flink 中如何管理配置?
29、Flink 从0到1学习—— Flink 不可以连续 Split(分流)?
30、Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
32、为什么说流处理即未来?
33、OPPO 数据中台之基石:基于 Flink SQL 构建实时数据仓库
36、Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
38、如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
40、Flink 全网最全资源(视频、博客、PPT、入门、原理、实战、性能调优、源码解析、问答等持续更新)
42、Flink 从0到1学习 —— 如何使用 Side Output 来分流?
源码解析
4、Flink 源码解析 —— standalone session 模式启动流程
5、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Job Manager 启动
6、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Task Manager 启动
7、Flink 源码解析 —— 分析 Batch WordCount 程序的执行过程
8、Flink 源码解析 —— 分析 Streaming WordCount 程序的执行过程
9、Flink 源码解析 —— 如何获取 JobGraph?
10、Flink 源码解析 —— 如何获取 StreamGraph?
11、Flink 源码解析 —— Flink JobManager 有什么作用?
12、Flink 源码解析 —— Flink TaskManager 有什么作用?
13、Flink 源码解析 —— JobManager 处理 SubmitJob 的过程
14、Flink 源码解析 —— TaskManager 处理 SubmitJob 的过程
15、Flink 源码解析 —— 深度解析 Flink Checkpoint 机制
16、Flink 源码解析 —— 深度解析 Flink 序列化机制
17、Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
18、Flink Metrics 源码解析 —— Flink-metrics-core
19、Flink Metrics 源码解析 —— Flink-metrics-datadog
20、Flink Metrics 源码解析 —— Flink-metrics-dropwizard
21、Flink Metrics 源码解析 —— Flink-metrics-graphite
22、Flink Metrics 源码解析 —— Flink-metrics-influxdb
23、Flink Metrics 源码解析 —— Flink-metrics-jmx
24、Flink Metrics 源码解析 —— Flink-metrics-slf4j
25、Flink Metrics 源码解析 —— Flink-metrics-statsd
26、Flink Metrics 源码解析 —— Flink-metrics-prometheus

27、Flink 源码解析 —— 如何获取 ExecutionGraph ?


